Data Pipeline
Jobs can define a Data Pipeline that can translate, transform, and enhance a dataset before being saved to the change log and/or sent to the target system. When applied at the source, the Data Pipeline executes before the Synthetic CDC operation (if engaged), but after the high watermark is applied against the source.
The execution of the Data Pipeline follows the order in which the pipeline components are listed. You can change the order of each component by using the up/down arrows.
To preview the data pipeline, click on the Run Data Pipeline button. Since the Target System uses the output of the data pipeline, if one is defined, it is important to execute the data pipeline before configuring the target system options.
When defining a Direct Job, a Data Pipeline can be defined both at the source and the target. The separation of the reader and writer operation allows multiple data pipelines to be executed, providing the flexibility needed to apply different processing logic based on the target. For example, if one of the targets is a TEST environment, the target data pipeline for the TEST system could mask the data before pushing the data.
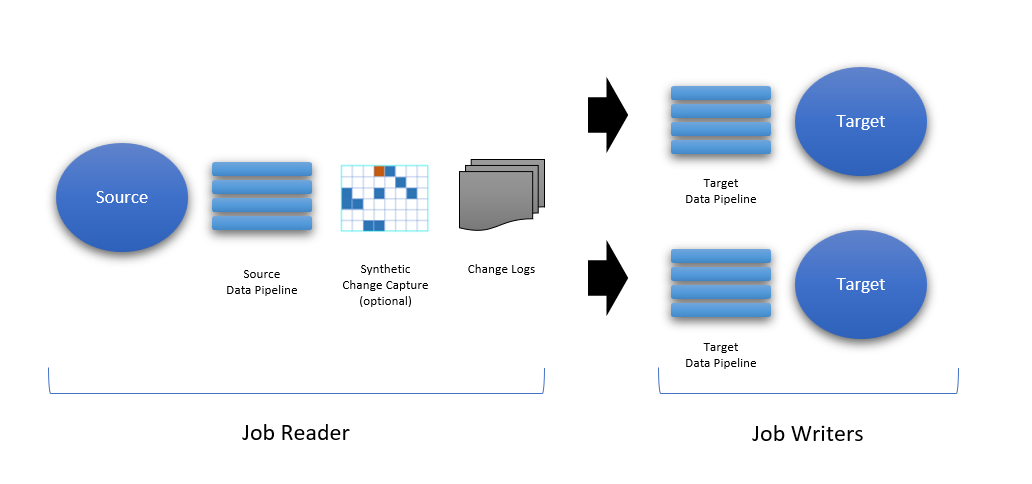
Building a Data Pipeline
The data pipeline interface provides a canvas for adding components that can translate or transform the data using pre-built data engineering functions. When the data pipeline is empty, you can run the pipeline to preview the source data; clicking on the Run Data Pipeline button executes the full pipeline. You can also inspect the schema of the data set at any time.
Running the data pipeline requires the reader (or writer) to have some sample data available; a warning will be displayed if no data is currently available.
To add pipeline components, click on the Add button and choose the component to add.
Using a Component
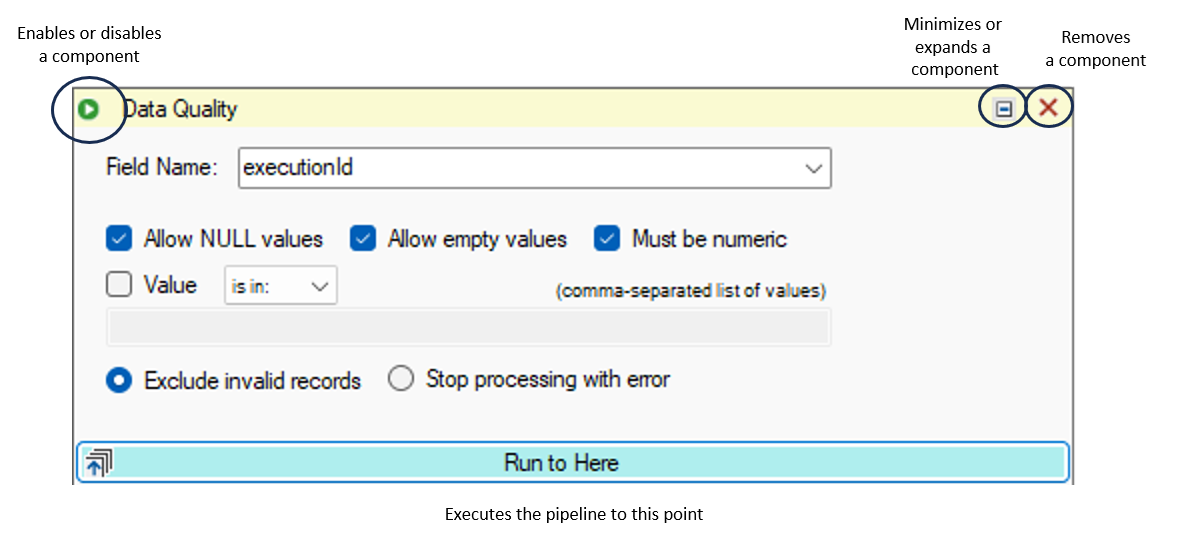
You can run a data pipeline up to a specific component to see the modified data set by clicking on the Run to Here button on the desired component; doing so will run the pipeline from the start until this point. In addition, the data set schema can be inspected at that point by clicking on the Inspect Data Schema button. Keep in mind however that when running the data pipeline partially, the schema may be incomplete and certain options in the Target get screen may not show the final schema.
You can disable and reenable a component by clicking on the top left icon; this allows you to test your pipeline without the component if needed.
Pipeline Components
The pipeline components available provide advanced data engineering functions that accelerate integration projects. For additional flexibility, it is also possible to inject a custom .NET DLL as part of the data pipeline.
The Custom .NET DLL component option is not available for Cloud Agents. Other components may be disabled based on your license.
| Category | Component | Comments |
|---|---|---|
| Data Transformation | Data Filter | Applies a client-side filter to the data by adding a SQL Where clause, a JSON/XML filter, or a regular expression as a Data Filter |
| Data Transformation | Data Masking | Applies masking logic to a selected data column, such as credit card number or a phone number. Supports generating random numbers, free-form masking, and generic / full masking |
| Data Transformation | Data Hashing | Applies a hash algorithm to a selected data column (must be a string data type); supported hashing algorithms are MD5, SHA1, SHA256, SHA384 and SHA512 |
| Data Transformation | HTTP/S Endpoint Function | Calls an external HTTP/S function or endpoint, and adds the results to the output or merges it with the input data. |
| Schema Management | Apply Schema | Transforms the data set schema as specified with optional default values and DataZen function calls. |
| Schema Management | Dynamic Data Column | Adds a column dynamically using a simple SQL formula, or a DataZen Function. |
| Schema Management | Keep/Remove Columns | Quickly remove undesired columns from the data set. |
| Transformation | JSON/XML to Table | Convert an XML or JSON document into a data set of rows and columns. |
| Transformation | CSV to Table | Convert a flat file document into a data set of rows and columns. |
| Change Capture | Apply Synthetic CDC | Applies an inline Synthetic Change Capture. |
| Staging | Sink Data to SQL | Sinks the current data set to a SQL Server table, optionally appending, truncating, or recreating it with automatic schema management. |
| Staging | Run SQL Command | Runs a SQL batch on the fly and optionally uses the output as the new data set in the pipeline. Can use @pipelinedata() to access the current pipeline data set. |
| Other | Data Quality | Inspects and applies data quality rules on the current data set. |
| Other | Custom .NET DLL | Calls an external custom .NET DLL, passing the current data set, and replaces the pipeline data set with the output provided. |
Example: Dynamic Column
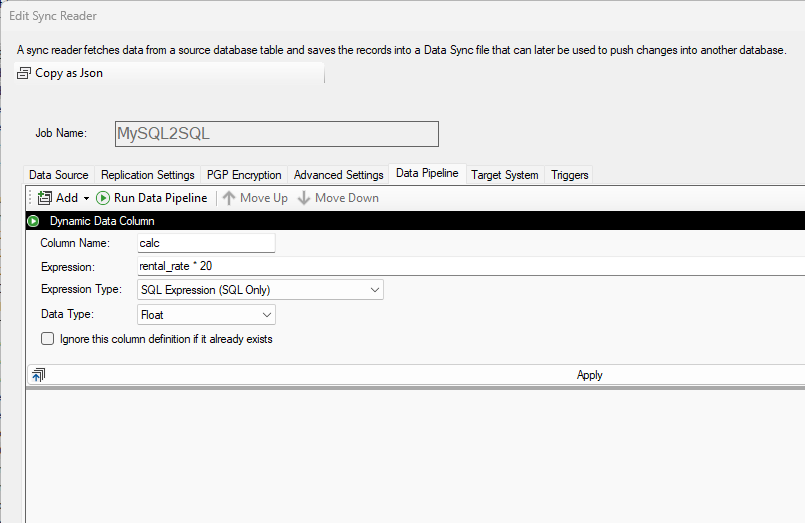
This example shows you how to add a new column calc to the source dataset with a float data type. The formula is a SQL Expression:
rental_rate * 20
See Microsoft's documentation on DataColumn.Expression Property for more information on the expected syntax.
When using a DataZen Function, you can use additional data transformation options.
Example: Custom .NET DLL
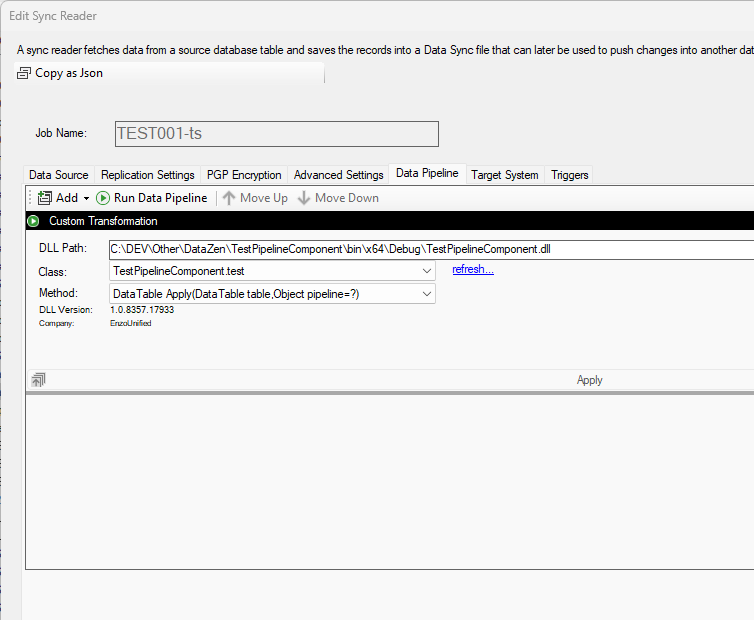
It is possible to call an external .NET DLL to perform more advanced transformations using the full capabilities of the .NET Framework. Once the DLL has been provided in the DLL Path, you can view the list of available public classes and methods.
The method must be named Apply and have one of the following signatures: public DataTable Apply(DataTable table) public DataTable Apply(DataTable table, dynamic pipeline) When accepting a second parameter, the list of connection strings used by the pipeline from other components will be provided as a serialized string.
The .NET DLL should be manually deployed on the server where the Sync Agent is running. The DLL Path provided should be the same on both the client machine and the server. The DLL itself is loaded into memory when the job starts and unloaded upcon completion.