Databricks
Databricks Connection
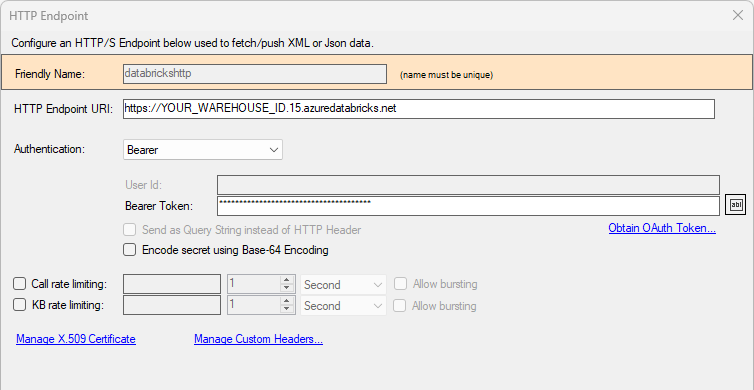
HTTP/S Endpoint
To connect to Databricks using an HTTP/S endpoint, create a new HTTP connection using DataZen Manager, and use the Bearer authentication mode. The bearer token can be obtained by inspecting your Databricks configuration settings.
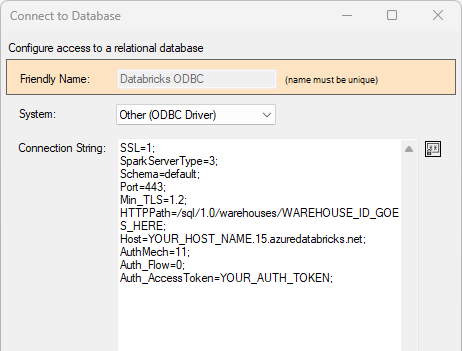
ODBC
To use an ODBC connection against Databricks, you must first download and install the Databricks ODBC driver (64-bit); then, create a new ODBC connection in DataZen with enough information for the driver to establish connection. If you already have defined a DSN entry on your local server, just specify this way:
DSN=mydsnTo enter a DSN-Less connection, enter the minimum number of properties required to connect to the endpoint; the following is an example to connect to an Azure Databricks warehouse:
DRIVER=Simba Spark ODBC Driver; SSL=1; SparkServerType=3; Schema=default; Port=443; Min_TLS=1.2; HTTPPath=/sql/1.0/warehouses/WAREHOUSE_ID_GOES_HERE; Host=YOUR_HOST_NAME.15.azuredatabricks.net; AuthMech=11; Auth_Flow=0; Auth_AccessToken=YOUR_AUTH_TOKEN;
Reading
HTTP/S API
Reading data from Databricks using an HTTP API call can be performed both Inline or using External Links.
The Inline option is the simplest method to use as long as you are not retrieving too much data at a
time (please refer to the Databricks documentation for more information on this topic).
Send a POST request to the /api/2.0/sql/statements/ endpoint and provide the request payload
that contains the SQL command to execute.
See the Job Reader - HTTP section for more information
on how to use the settings found on this page. The following JSON document is an example of a valid HTTP payload:
{
"warehouse_id": "abcdef0123456789",
"statement": "SELECT * FROM range(100)",
"wait_timeout": "30s"
}
To read the response payload directly from the Job Reader, you can use the Payload Tx option and specify the Document Root Path as:
$.result.data_array.
Depending on the time it takes for the command to execute, the response payload may contain a GUID value for the request, with a status of PENDING. You can use this GUID as part of the Data Pipeline to request the data or a secondary Job Reader to fetch the result.
ODBC
Reading data from Databricks using an ODBC driver is similar to all other relational database sources; simply type the SQL command you would like to execute, and optionally specify the @highwatermark marker to retrieve data from a specific point in time. See the Job Reader - Databases section for more information.
Writing
HTTP/S API
Writing data to Databricks using an HTTP API call can be performed by sending a
POST request to the /api/2.0/sql/statements/ endpoint and provide the request payload
that contains the SQL command to execute.
Three areas of interested are highlighted in the screenshot below:
- Batch Count: This setting controls how many records will be merged at a time, per HTTP request; it is used by the @sql_union() operator which will inject up to 50 records every HTTP call in this example
- Single Line: Since the JSON specification does not support text over multiple lines, the @singleline() operator converts its inner content into a single line by removing all carriage returns and line feed markers.
- Build SQL Payload: use this helper window to help you build the desired SQL command by choosing the update strategy (append only, merge, or delete) and which fields should be used for the JOIN operation.
{
"warehouse_id": "abcdef0123456789",
"statement": #singleline("
MERGE WITH SCHEMA EVOLUTION
INTO `target2` target
USING
(
@sql_union(SELECT { { id} } as `id`, '{{stateCode}}' as `stateCode`)
) source
ON source.`id` = target.`id`
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
"),
"wait_timeout": "30s"
}ODBC
Writing data to Databricks using an ODBC driver is similar to all other relational database targets; simply type the SQL command you would like to execute. See the Job Writer - Databases section for more information.
COPY INTO
You can easily implement a COPY INTO mechanism with DataZen by creating Parquet Files containing the new data into an S3 bucket or an ADLS 2.0 target. By naming the files with a unix timestamp, you can always ensure each file to be loaded is unique. See the Job Writer - Drive section for more information on how to sink data into files.
Once the DataZen pipeline is configured to create files of new and updated records into a cloud drive
endpoint, you can simply configure a Databricks pipeline to ingest all newly created files using the
COPY INTO operation, and leverage the COPY Tracking feature of Databricks. The sample code below
assumes that each data pipeline will have a unique target temporary table (called databases_tmp below).
-- Create a temporary table to stage incoming data leveraging the COPY tracking feature
CREATE TABLE IF NOT EXISTS databases_tmp;
DELETE FROM databases_tmp;
COPY INTO databases_tmp
FROM 'abfss://test@adls20endpoint.dfs.core.windows.net/'
FILEFORMAT = PARQUET
FORMAT_OPTIONS ('mergeSchema' = 'true', 'inferSchema' = 'true')
COPY_OPTIONS ('mergeSchema' = 'true');
-- Merge the incoming data into the target table
MERGE WITH SCHEMA EVOLUTION INTO databases
USING databases_tmp as source
ON source.database_id = databases.database_id
WHEN MATCHED THEN
UPDATE SET *
WHEN NOT MATCHED THEN
INSERT *
;