Run SQL Command
Use this component to execute a custom inline T-SQL script using the current pipeline data set and optionally change the data set of the data pipeline with the result. This component is normally used to performed advanced transformations on the data using the full power of a database engine, including XML or JSON transformations, JOIN operations on fact tables, GROUP BY operations, or call stored procedures for extensive data operations.
This component requires the use of a supported database engine (such as SQL Server, MySQL, Postgres...) in order to run the script.
Select a database connection from the dropdown list of connections and enter your SQL script. You can choose an execution timeout (in seconds) by setting the Exec Timeout value, and optionally choose to replace the current data pipeline data set with the output data set of the SQL script by checking the Replace dataset with this result. You can optionally choose to continue the pipeline execution on error by checking the Continue on error option.
Using @pipelinedata()
To access the current pipeline data set, you can use the @pipelinedata() token in the SQL script anywhere. It can
be referenced multiple times. Behind the scenes, this token will automatically sink the data (using the Sink Component), replace the
@pipelinedata() token with the temporary table name created, and once the script is completed the temporary table will be dropped.
For example, to access the current pipeline data, run this command:
SELECT * FROM @pipelinedata()
Accessing Job Runtime Variables
You can access all available Job Runtime Variables, such as the current @executionid. For example, the following script
adds the execution id as a new column:
SELECT *, execid = '@executionid' FROM @pipelinedata()
You should validate that your T-SQL script does not itself use variable names that would conflict with DataZen's Runtime Variables or you may experience compilation errors. For a list of variables used by DataZen, see the Job Runtime Variables section.
DataZen Functions
You can execution DataZen functions at the script level. In this component, DataZen functions are evaluated once before running the script.
For example, a single Random GUID value can be generated:
SELECT *, newuid = '#rndguid()' FROM @pipelinedata()
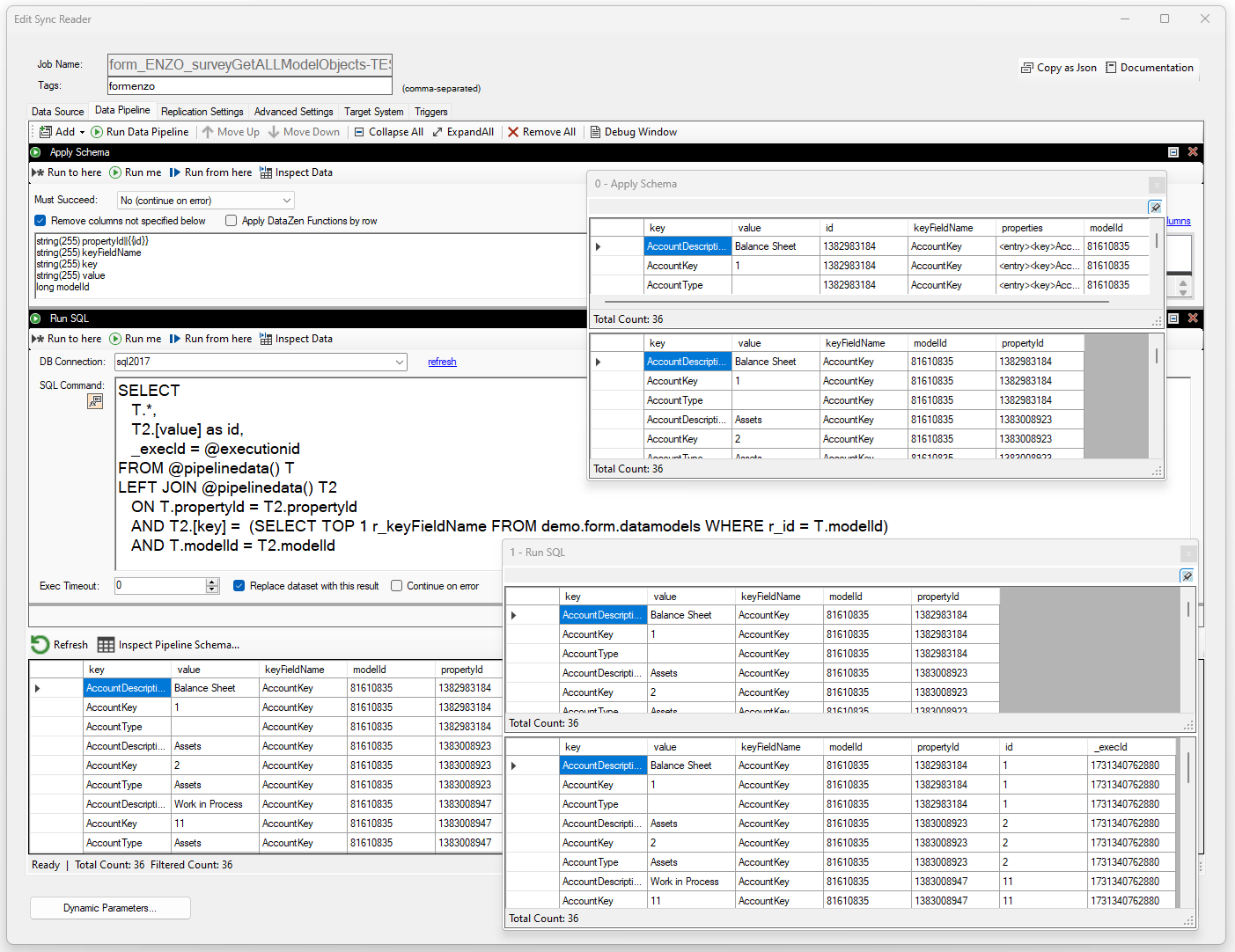
Example
In this example, we are performing two operations: first, an Apply Schema to limit the number of columns being processed and ensuring specific data types, then a complex JOIN operation on the data to itself to extract a leading value used as a new surrogate key downstream. Note that the @pipelinedata() is joined on itself in this example.
SELECT T.*, T2.[value] as id, _execId = @executionid FROM @pipelinedata() T LEFT JOIN @pipelinedata() T2 ON T.propertyId = T2.propertyId AND T2.[key] = (SELECT TOP 1 r_keyFieldName FROM demo.form.datamodels WHERE r_id = T.modelId) AND T.modelId = T2.modelId