HTTP Endpoint
This component allows you to call an external HTTP/S endpoint to replace or enhance your current data set, on the fly. As an example, you can call an OpenAPI endpoint in the cloud that analyzes images and returns information about the content of the image. You can also call a custom external HTTP/S cloud function, such as AWS Lambda or Azure Function.
HTTP/S Call Settings
First, select an existing HTTP/S connection, then choose the HTTP Verb (GET, POST, PUT, DELETE) and enter the HTTP URL to call. You can use DataZen functions to build this URL if needed. You can also add custom headers if needed.
URI and Headers
Although URIs and Headers can use DataZen functions to assist with more advanced endpoints, only the Per Row processing
mode allows you to also use field values as part of either. For example, if Per Row is selected, you can
also pass field values using the {{field}} notation, in the URL and Headers.
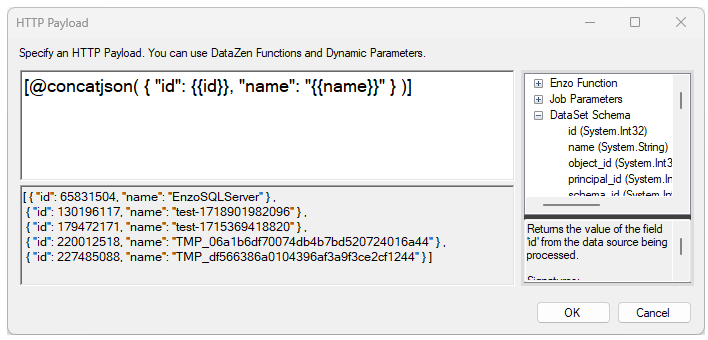
HTTP Payload
When the HTTP verb is a PUT or POST operation, the Payload link is enabled. Clicking on it allows you to enter a payload to be sent to the endpoint. When the Per Row operation is used, the document will represent a single record; all other options allows you to build a payload with all available records. For more information on how to build payloads, see the Formatting Documents section.
Processing Mode
The Processing Mode setting dictates how many times the endpoint will be called and how the result will be handled. The following modes are available:
- Continue: The current pipeline data remains unchanged; any data returned will be ignored by the next pipeline component
- Replace Dataset: The data returned by the HTTP endpoint will replace the current pipeline dataset; a single call is made to the HTTP endpoint; the Tx Root Path can be used to transform the payload into rows and columns
- Per Row: The data returned by the HTTP endpoint will be merged with the current pipeline dataset using a Left Join mode; the HTTP endpoint will be called for each row in the current pipeline data; the Tx Root Path can be used to transform the payload into rows and columns
- Enhance Dataset: The data returned by the HTTP endpoint will be added side-by-side with new columns, with optional shifting; the HTTP endpoint will be called once; the Tx Root Path can be used to transform the payload into rows and columns
When using the Continue mode, any data returned by the HTTP call will be discarded. However, you can still sink the response data directly into a database for later inspection, or to retrieve in future pipeline components (ex: the Run SQL component). This pattern allows you to keep the current pipeline data set as the main driving data flow for your data pipeline while keeping the ability to access the HTTP results later. Since the logging operation includes the Execution Guid of the current execution pipeline, you can always find out which record belongs to the current pipeline execution.
When using the Replace Dataset mode, the current data pipeline dataset will be discarded and replaced with the result of the HTTP call.
By default, the result will include a few fields with HTTP operation details, including the payload field, which contains the response
content. If you expect this call to return an image or a document, check the Return Byte Array Output under Advanced to also include
the payload as a byte array.
When using the Per Row processing mode, the calls made to the target HTTP Endpoint are performed sequentially, one input row at a time.
If the current pipeline data set has 100 rows, this processing mode will make at least 100 calls to the HTTP Endpoint. Retry conditions could
impact the total number of calls actually made. When constructing the URL and payload for each call, the current row values will be used. For
example, if the current data pipeline has an id field, the following HTTP URL will be recalculated for every row:
https://myendpoint/getdata/{{id}}. Finally, each HTTP call made is joined with the current row; if the response of the call
generates more than one record for any given call, the same input row will be duplicated as many times as needed as a Left Join operation.
For example, if you have 2 input rows of images and call a Vision endpoint that returns 10 properties for each image that describes the image,
the pipeline will have 20 rows after completion.
When using the Enhance Dataset mode, the HTTP endpoint is called once, but the assumption is that the returned payload matches the
input record count. The resulting payload can be transformed into rows and columns as well, in which case multiple columns will be added
dynamically to the current pipeline data. For example, you have an incoming data pipeline with customer information and you would like to send
a single request to an HTTP endpoint that returns the last known email address and phone number. This operation expects that if 100 records exist
in the incoming pipeline data set, the payload send back by the HTTP endpoint will contain a document with 100 nodes. However, in some cases,
endpoints may return fewer records, such as statistical endpoints (for example, a moving average calculation). You can use the shift rows
option to skip the first "n" record to align the results correctly.
Logging
This tab provides options to log the HTTP result into a database table. You can optionally log the payload sent as well. Use the Show payload in debug output to visualize the payload sent when debugging requests.
Advanced
If the HTTP endpoint returns binary data, such as a PDF document or an image, check the Return Byte Array Output so that
the raw binary data is available in the response.
Use Continue on Error to prevent the pipeline from failing if an error is detected.
This option should only be used if the call to the HTTP endpoint is not important to the overall success of the pipeline.
You can control the HTTP call timeout by changing the Request Timeout option.
Retry Condition
In certain cases, the HTTP Endpoint may return with a temporary message instead of the result payload. You can choose to inspect the return message and try calling the endpoint again after a short period of time. To do so, check the Retry request if body contains option and fill out the necessary details. If the document returned is an XML or JSON document you can also specify an XPath or JSON Path to extract a specific node value. The text provided in the Contains box will be used; check the Regex Match option if this text should be treated as a regular expression. Finally, change the interval of each retry in seconds and the maximum number of retries.
Example
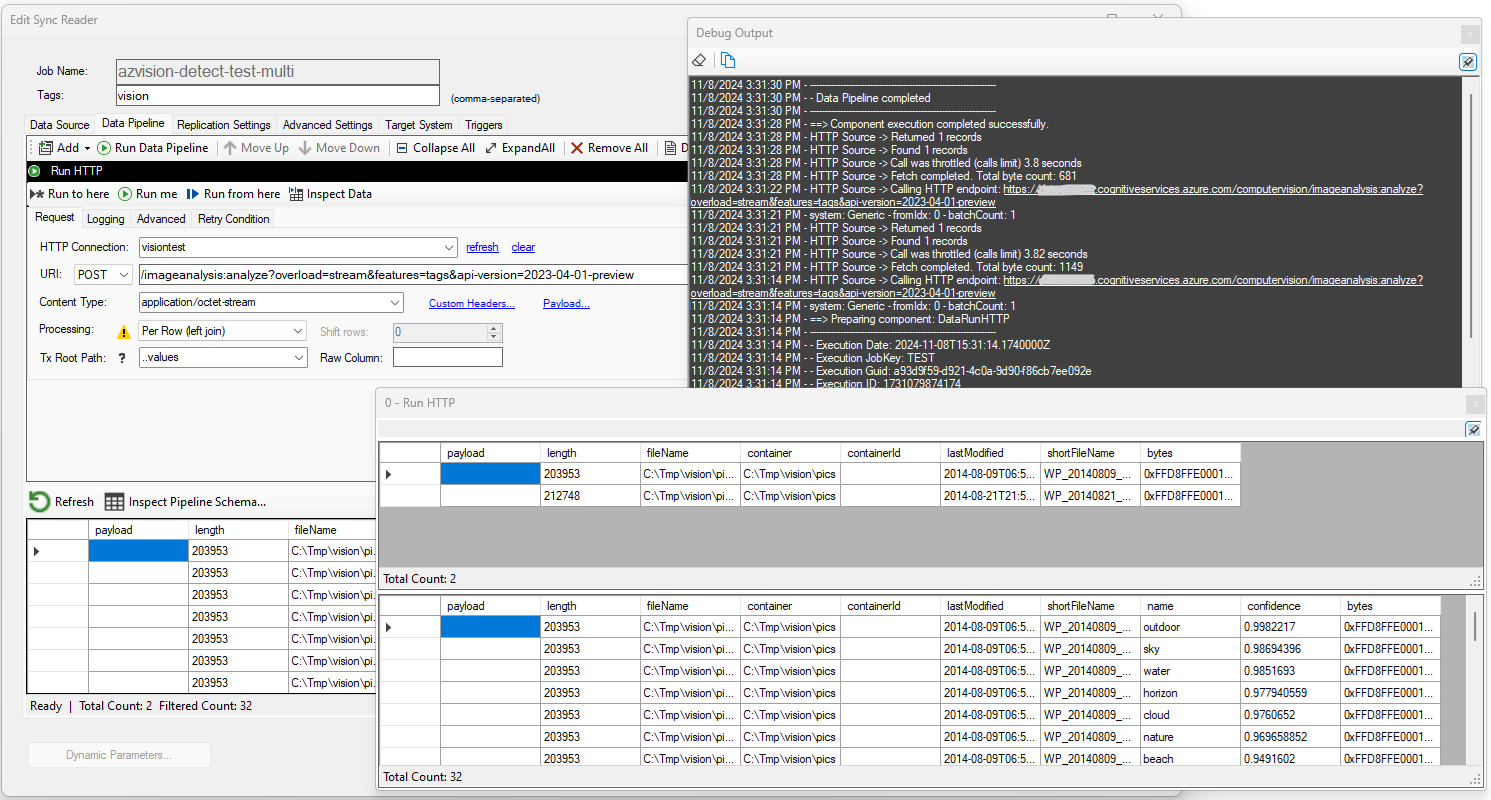
In this example, the source data represents two files read from a local drive. The bytes column represents the binary
representation of the file. The HTTP Endpoint is an Azure Vision OpenAPI service running in the cloud, that returns image tags
providing information about the content of each image. Because we want to call the OpenAPI endpoint for each file, we choose the
Per Row processing mode. The Payload of the request contains the image itself passed in as
hexadecimal content: {{hex:bytes}}.
Each call to the vision endpoint returns a JSON document with the list of tag names and a confidence level; because
we are also choosing the convert this JSON document using the ..values JSON Path, the results are joined to provide
the new pipeline dataset with both input and the resulting HTTP output.