EXEC
Overview
The EXEC operation allows you to execute a database batch operation and optionally transform the current pipeline data set inline, without having to store it first. Any valid T-SQL script is accepted, with the option to include pipeline variables and DataZen functions.
The @pipelinedata() function is only available in this component.
It is used to access the current pipeline data set inline any number of times.
You can treat this function as a regular table, so you can perform JOIN operations on it
as needed.
You can use go; on a single line to create multiple batches of operations.
This can be useful if you would like to add indexes on the @pipelinedata() table for example
or perform other DDL operations that must be executed separately.
Use the REPLACE option to change the pipeline data set. This allows you to replace the pipeline data entirely.
This component executes a database script against SQL Server databases only; it does not currently support other database engines.
Syntax
Executes an inline SQL Batch operation on a database engine and optionally replaces the pipeline data with the output of this operation; use @pipelinedata() to access the current pipeline data set.
EXEC ON DB [CONNECTION]
(...)
{ WITH
{ PER_ROW }
{ REPLACE }
{ TIMEOUT N }
{ CONTINUE_ON_ERROR }
}
;PER_ROW |
Executes the SQL block per row of data in the pipeline (field replacement will be performed) |
REPLACE |
Indicates the output of this batch operation should replace the current pipeline data |
TIMEOUT |
The execution timeout in seconds |
CONTINUE_ON_ERROR |
Continues processing even if errors are detected |
Example 1
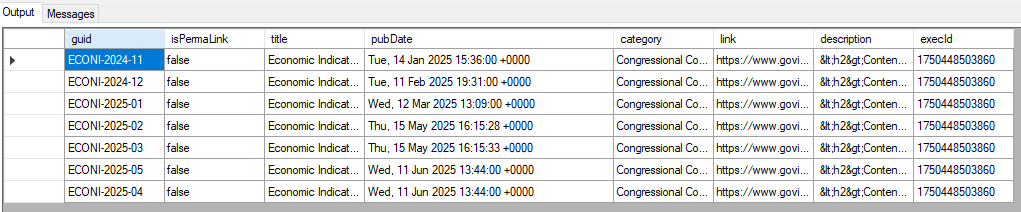
-- Get data from an RSS Feed SELECT * FROM HTTP [Rss Feed] (GET /econi.xml) APPLY TX (//item); -- Executes a SQL Batch operation on a SQL Server database -- This call does not modify the pipeline data set upon completion EXEC ON DB [sql2017] ( INSERT INTO [mydb]..[table1] (execId) VALUES (@executionid) );
Example 2
-- Get data from an RSS Feed SELECT * FROM HTTP [Rss Feed] (GET /econi.xml) APPLY TX (//item); -- Executes a SQL Batch operation on a SQL Server database -- This call retrieves the current pipeline data, filters it, and returns -- the data as the new pipeline data set EXEC ON DB [sql2017] ( SELECT @executionid as execId, * FROM @pipelinedata() WHERE [pubDate] like '%2025%'; );