Job Reader: HTTP
Reading and extracting from HTTP/S data sources is made simple with DataZen. However, many options are available and may require fine-tuning depending on the service. This section provides a high-level overview for creating new HTTP/S Job Readers.
To create a new HTTP/S Job Reader, you must first have configured an HTTP/S Connection. Then, from DataZen Manager, click on the New HTTP Job menu item.
If the service you are trying to call offers an Open API specification, Swagger definition, or a Postman Collection, click on the HTTP URL link. DataZen offers a few pre-configured services as well. This special Wizard allows you to quickly configure HTTP/S calls and save your own specifications locally for future use.
Build HTTP/S From Existing Specification
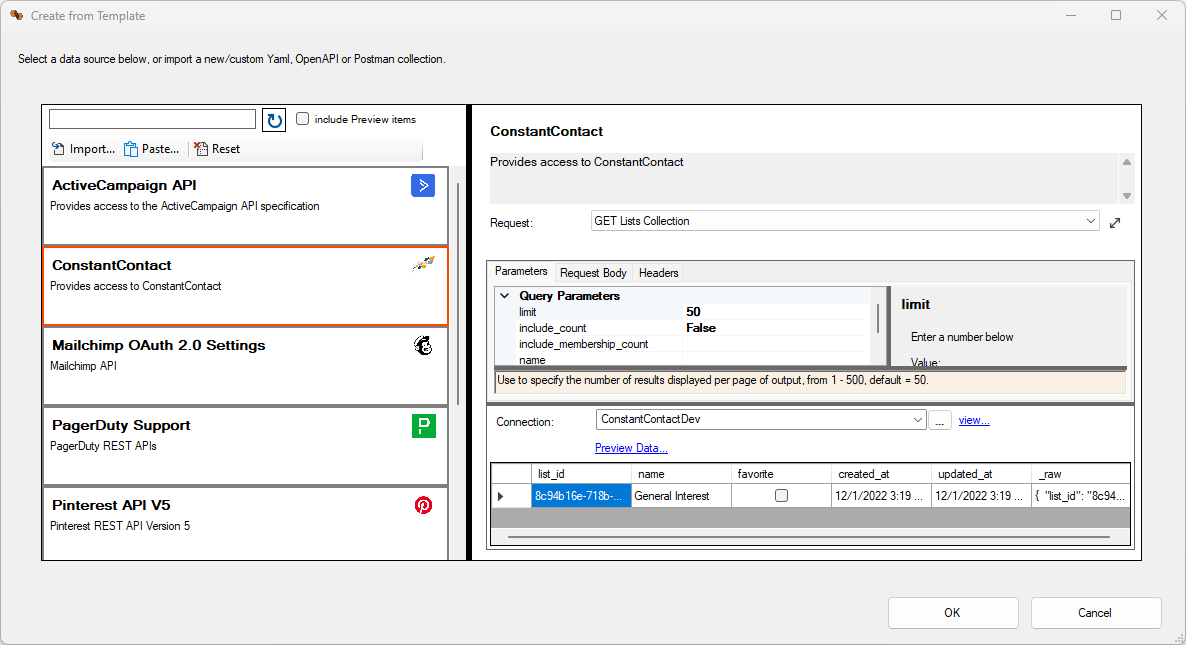
To open up the HTTP/S call builder, click on the HTTP URL link. Choose from a list of existing HTTP/S templates or add your own Open API, Swagger, or Postman collection.
This screen has three sections: a list of existing services on the left, the list of
available HTTP/S calls top right, and a sample output bottom right. You can modify the
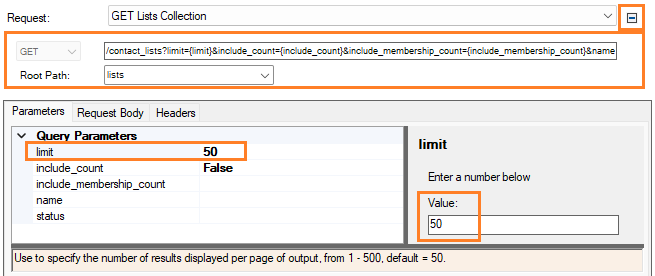
actual URL called and change default parameters before sending the request, including
HTTP Headers and the body for POST, PUT and PATCH requests.
Click on the preview data link at the bottom to send the request.
Set HTTP Options
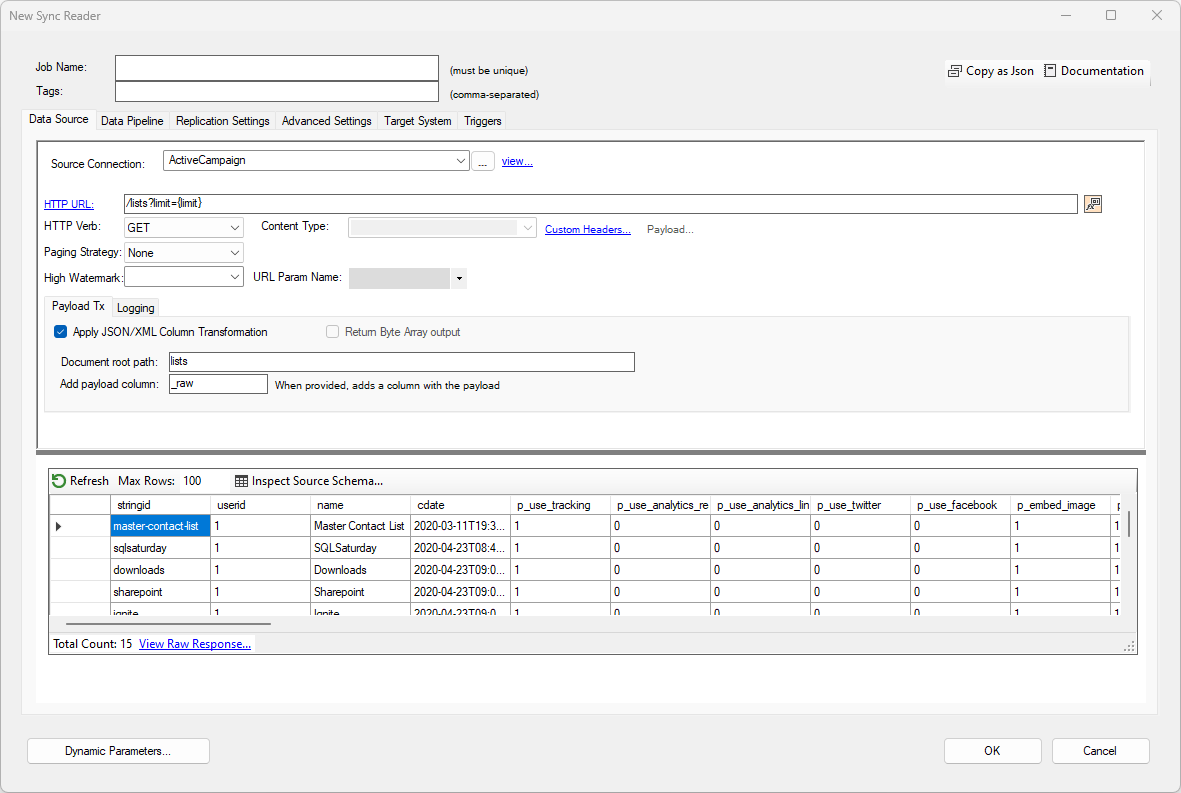
From this screen, enter a unique job name and modify the
Content-Type and Payload for PUT, POST and PATCH operations.
By default, the output will be the full HTTP response payload, and optionally as a byte array
if the options is selected. Most HTTP responses provide a complex result set either as a JSON or XML document.
You can automatically convert an HTTP payload into a data set automatically using
the Document Path option.
HINT: If you are not sure which path to set, click on the View Raw Response link; a window will be displayed with the full content payload. When you change the Path and press the enter key the payload will be reprocessed to show the updated data set.
High Watermark
The High Watermark setting allows DataZen to modify the HTTP request (URL or payload) in order to receive changes from the last high value received. To configure the high watermark, use the following settings:
- High Watermark:Type or select the field in the response payload to calculate the high watermark
- URL Param Name:If the high watermark should be passed into the URL as a Query Parameter, type the name if the field that should be added to the URL path. To use the high watermark value inside a request payload instead or as part of a URL parameter that should be modified dynamically, leave this field blank, and use the @highwatermark token in the payload or the URL directly
This setting only works when the payload is transformed into a data set.
Example: Query Parameter
In this example, a high watermark value is extracted from the updated_at field returned by the data set, and then used as the updated_after query parameter. If the parameter is not already provided in the URL, it will be added automatically subsequently. It if already exists, it will be replaced with the current high watermark value or removed if the value is NULL (the high watermark value is NULL when the job runs the very first time).
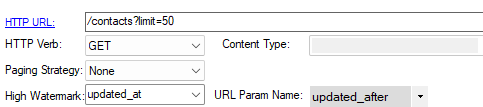
Example: Customer Query Parameter
In this example, a high watermark value is extracted from the ModifiedDate.LastUpdatedOn field returned by the data set, and then used
as in the query parameter using the @highwatermark token. Note that the URL Param Name field is left blank on purpose.
This way, the token can be used any way necessary as part of the URL or the payload. This example shows an HTTP command that accepts a
SQL query as part of a query parameter (QuickBooks Online). Since the high watermark
is NULL the first time the job is executed, a DataZen function is used to set a default value:
#isnullorempty(@highwatermark, 2020-06-25T00:00:00)

Paging Strategy
A paging strategy allows DataZen to fetch source records over multiple calls to fetch the "next"
set of data. Certain HTTP APIs limit the number of records returned by applying a
maximum (limit) to the data set (for example, Twitter). Setting this value requires
an understanding of the paging capabilities of the HTTP API being queried.
The following paging strategies are available:
- None: No paging logic is applied; the HTTP API is called once
- Simple Offset: DataZen keeps a count of records retrieved; it uses the current record count as its "next" page using the URI Parameter specified Simple Paging: DataZen keeps a count of calls made; it uses the "page" count as its "next" page using the URI Parameter specified
- Reference Link: DataZen uses a full HTTP URI provided within the JSON HTTP response and uses it "as-is" for its next call. This setting requires a JSON or XML Path to be specifed (see the JSON or XML Path section below)
- Bookmark/Token: DataZen uses a Bookmark or Token value provided within the JSON HTTP response and uses it for its next call using the URI Parameter specified. This setting requires a JSON or XML Path to be specifed (see the JSON or XML Path section below)
HTTP Logging
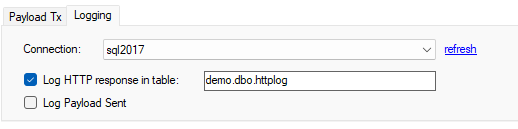
To log all HTTP/S responses including header, and optionally the payload sent, select the Logging tab, select a database server, and specify a table name. You can use the same table with multiple jobs; the table will be created if it doesn't exist and has enough information to allow you to filter by job name.
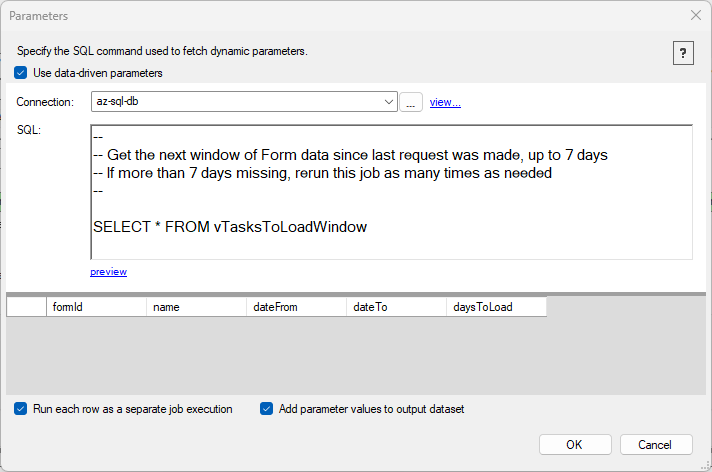
Dynamic Parameters
Dynamic Parameters allow you to specify variables to be used as part of the HTTP call;
each row of values will be executed as a separate HTTP call. The values to be used can
be stored in a database table so you can control the parameters externally.
To use the parameter, use this notation within the HTTP URI: {{@param.variablename}}
For example, if you would like to fetch the twitter feed from multiple Twitter accounts,
you would create a Dynamic Parameter that returns the Twitter ID for these accounts; here
is a sample SQL command that returns 3 IDs, and the column name is 'userId':
SELECT '15358364' as userId
UNION SELECT '14934774'
UNION SELECT '2389949911'
Then, the URI would look like this (note the use of the userId parameter in the URI):
https://api.twitter.com/2/users/{{@param.userId}}/tweets?expansions=entities.mentions.username&tweet.fields=created_at,author_id&user.fields=username&max_results=100
When the job executes, it will replace the 'userId' parameter for each available entry.
If you use a High Watermark along with Dynamic Parameters, the first column returned by the Dynamic Parameter SQL command must be unique; internally DataZen uses the first column as the key for storing the last known High Watermark value.
In this example, the dynamic parameters are returned by a view stored in a database. This is an advanced implementation pattern in which the high watermarks are kept programmatically in the database, and provided by this view. If the view returns 0 records at the time the job executes, the job skips since there nothing to do.
Two options are provided in this screen:
- Run each row as a separate job execution: when checked, each row will be treated as a separate job execution, and a new execution id will be generated
- Add parameter values to output dataset: when checked, the columns will be added to the output data set, and the values of each row will be returned
When running a cloud agent, the number of rows returned by this option may cause the job to run much longer since each row will be used as a job operation. If the job takes more than 5 minutes, it may be aborted by the cloud platform without warning.