High Watermark
A high watermark pattern allows you to request data from a source system from a specific point in time, or last known high value, so that only a subset of records are returned. This pattern provides the best possible performance and minimizes resource consumption; the method to implement a high watermark depends somewhat on the source system. Using a high watermark without Change Capture is normally used for detecting both inserted and updated records.

Pattern Overview
This pattern describes a forward-only read from the source system using a high watermark
without the need for Synthetic CDC or a sliding window. When the source systems provides a
way to select a subset of data, this pattern can be useful to capture changes from a point in time,
on a go-forward basis.
Various fields can be used for tracking a high watermark, including datetime values, numeric fields,
or timestamp bytes.
In some cases, you may need to track two high watermark values: one for capturing new or updated records,
and another for capturing deleted records; this may be necessary when the source systems offers different
feeds for deleted records, and is usually limited to HTTP/S systems.
| Column Name | Data Type | Description |
|---|---|---|
| ID | long | A unique identifier |
| CustomerName | string | The customer name |
| LastUpdatedOn | datetime | The date of the last change |
Example of a table that supports the use of a high watermark using the LastUpdatedDate field
Not all source systems provide filtering capabilities. If a source system does not provide such mechanism, this pattern cannot be used.
DataZen Implementation
Using high watermark values is implemented differently in DataZen depending on the source system. Once a pipeline job is configured for high watermark tracking, DataZen automatically stores and uses the watermark on subsequent calls.
| Source System | High Watermark Supported | Comments |
|---|---|---|
| Relational Database | Yes | Support is provided against all relational engines, either applied automatically for simpler SELECT commands
or using the @highwatermark or @highwatermarknull parameter as part of the SQL query
|
| HTTP | Yes | Support is provided for query parameters and payloads as long as the API supports filering |
| Drive | Yes | Support is provided against all drives using the internal system date of the file (last updated) |
| Big Data / NoSQL | No | Support is provided using the @highwatermark or @highwatermarknull token as part of the SQL query |
| Messaging Consumers | No | Not applicable |
An administrator can modify the high watermark value if needed.See the High Watermark help section for more information.
Database Source
When the source system is a relational database, DataZen simplifies high watermark tracking by simply selecting the column of the source data that will be used for this purpose. To do this, from the Source tab, select a database connection and enter an SQL command; then click Refresh to load the data.
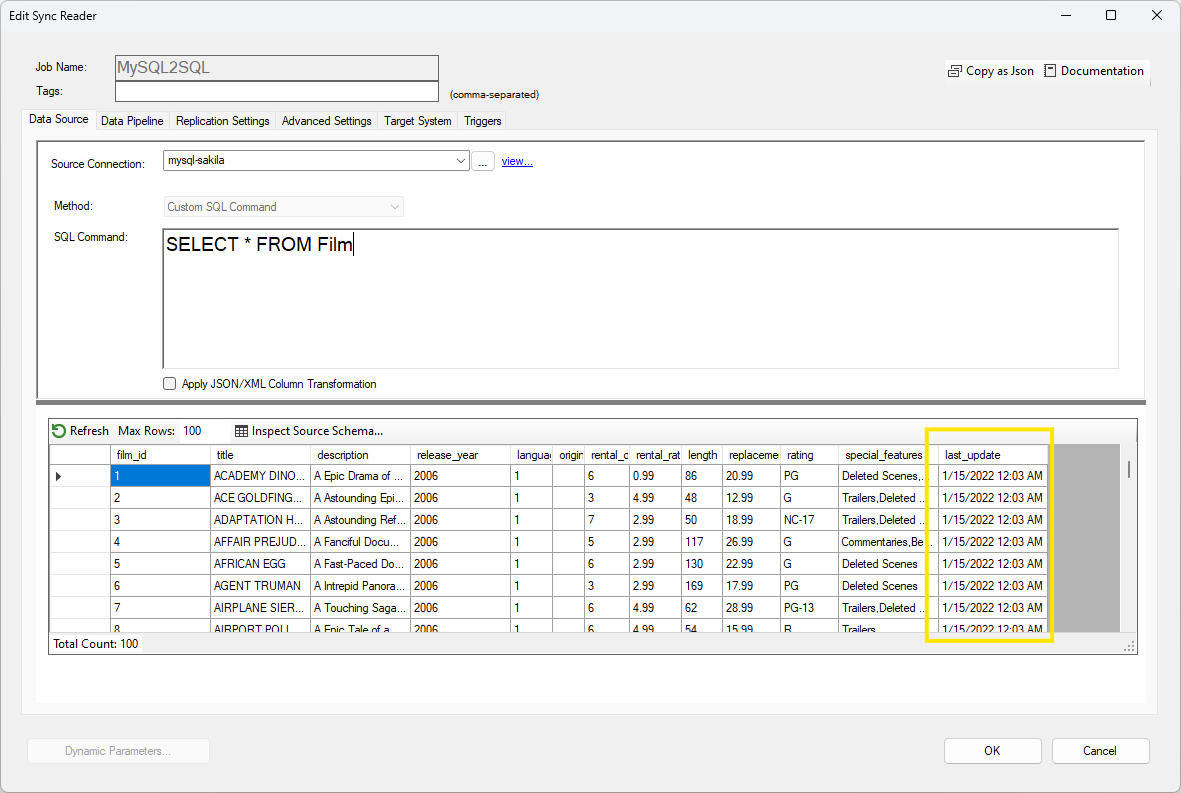
Once you have retrieved some data, go to the Replication Settings tab, and select the desired field for the High Watermark. In the example below, the last_update field will be used as the high watermark.
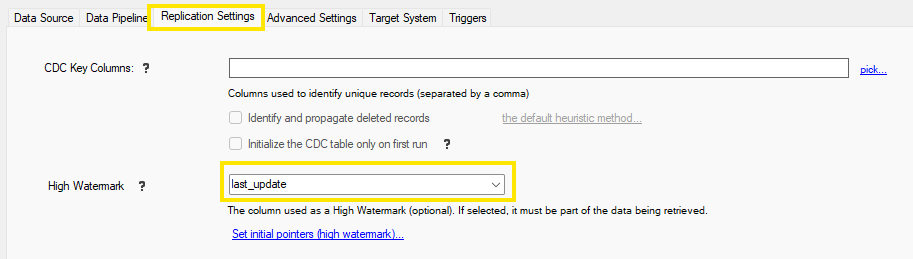
When you save this pipeline, DataZen will automatically modify the SQL command dynamically to inject the latest
high watermark value. You can also specify an initial high watermark value by clicking on Set initial pointers.
When using this automated heuristic for high watermark values, the source SQL command must be a simple SELECT operation.
Using very complex SELECT operations, or functions/procedures will not work and may throw an error. When dealing
with complex commands, use the @highwatermark or @highwatermarknull parameter instead.
Using the @highwatermark token
When more control over the high watermark is needed, you can add the @highwatermark or @highwatermarknull
parameter directly as part of the SQL command. Ex: EXEC GetDataFromLastDate '@highwatermark'. When using the
parameter directly in the SQL query, it is initially set to an empty string the first time the command executes, unless you
override the default value manually by clicking on the Set initial pointer... link, when available.
HTTP/S Source
Using a high watermark with HTTP sources depends on the ability of the API to handle HTTP requests with input parameters, either as part of the URI (as a query parameter) or the payload (usually in the form of a POST or PUT request) such as a GQL (Graph Query Language) request.
As a Query Parameter
When specifying a high watermark as part of the URL, using a query parameter, you need to specify two settings: the High Watermark field from the data being returned by the API, and the URL Param Name field to indicate the name of the parameter to modify dynamically when sending the request.
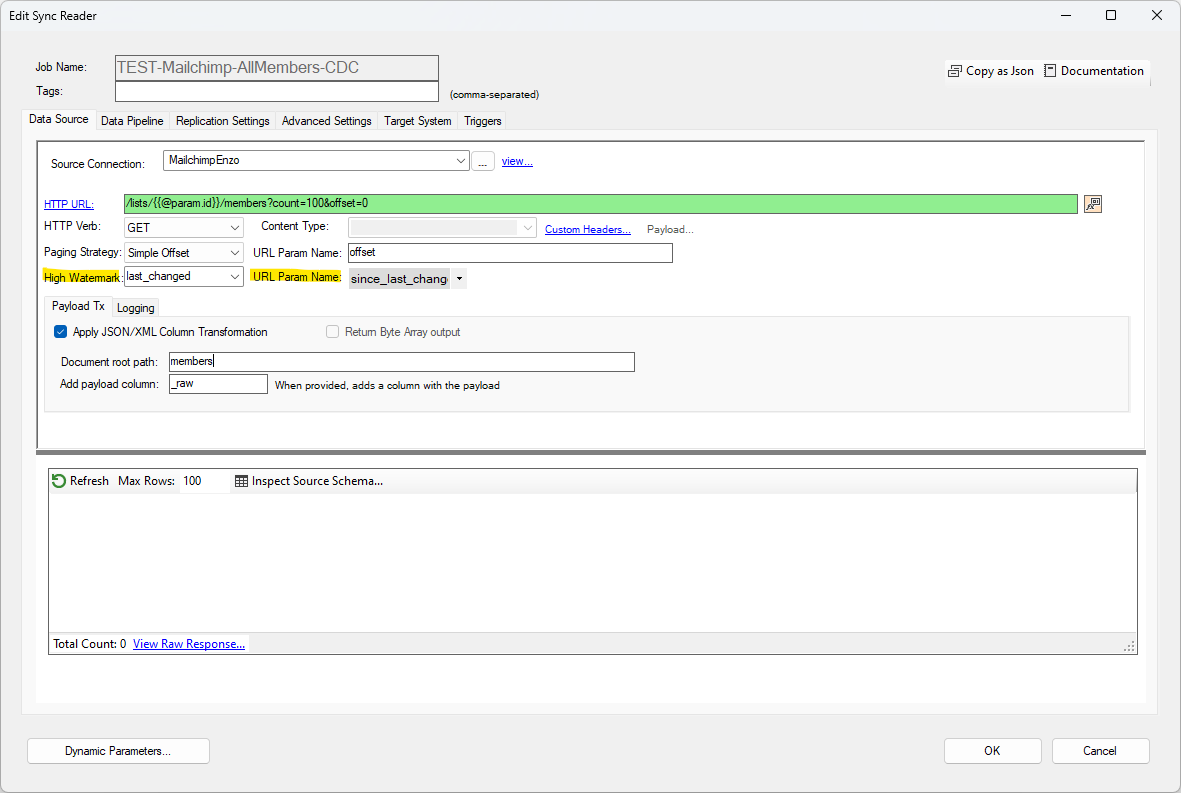
In the above screenshot, the data returned is first turned into a dataset (using the JSON/XML transformation); the last_changed field is then used to extract the high watermark. Then, or subsequent requests, the since_last_changed URI query parameter will be added automatically to the HTTP request.
You can also customize the value passed as part of the URI parameter, such as applying a date format, or specifying a
default value if the high watermark is not yet defined (for example, the first time you run the pipeline). To do so,
leave the URL Param Name field empty, and use the @highwatermark or @highwatermarknull
variable instead as part of the URI.
In the example below, the query specifies the filter parameter as required by the API for Business Central:
filter=lastModifiedDate gt #isnullorempty(@highwatermark, 2000-01-01T00:00:00.000Z)

As a Payload
When specifying a high watermark as part of the HTTP payload, you need to provide the High Watermark (the field
from the data being returned by the API that contains the value), and leave the URL Param Name field empty.
Then, use one of the watermark or token runtime parameters in the body as needed (for example @highwatermark,
@highwatermarknull , @pagingmarker, @pagingindex...).
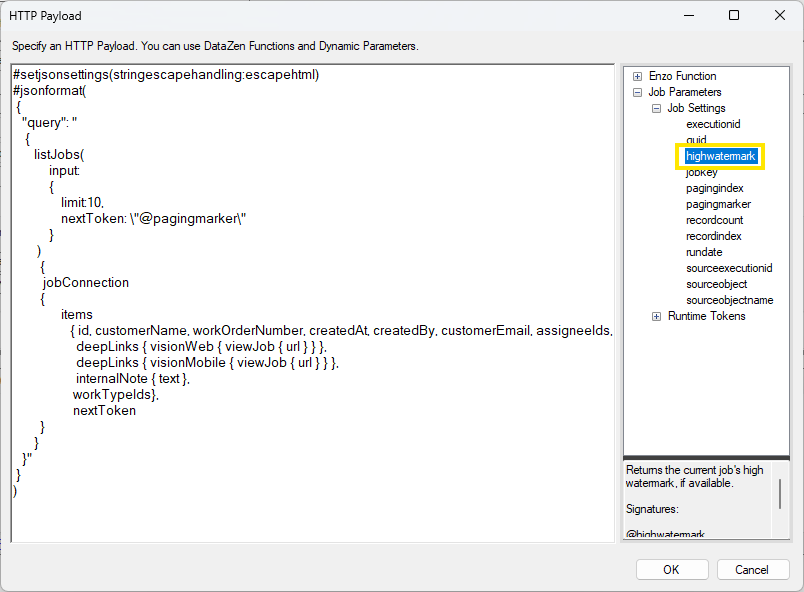
In the above screenshot demonstrating a call to Sage Intacct, the WHENMODIFIED field is used as a high watermark,
which is expected to be a date/time value, and used
as part of the HTTP Payload. Using the #isnullorempty() function sets a minimum value during first-time initialization,
and the surrounding #dateadd() function goes back 10 days as a windowing technique.
Choosing Treat HWM as a DateTime value is important because some APIs return a date value that is not sortable, which prevents calculating the correct next high watermark value; this option tells DataZen to treat the return field as a datetime value for ordering purposes.
Normally, the @highwatermark is sufficient in most cases to capture changes. However, in this scenario, the Sage Intacct
API does not always update the WHENMODIFIED field depending on the change made; as a result, a windowing technique
is necessary due to limitations imposed by the API. See the window capture pattern.
Drive Source
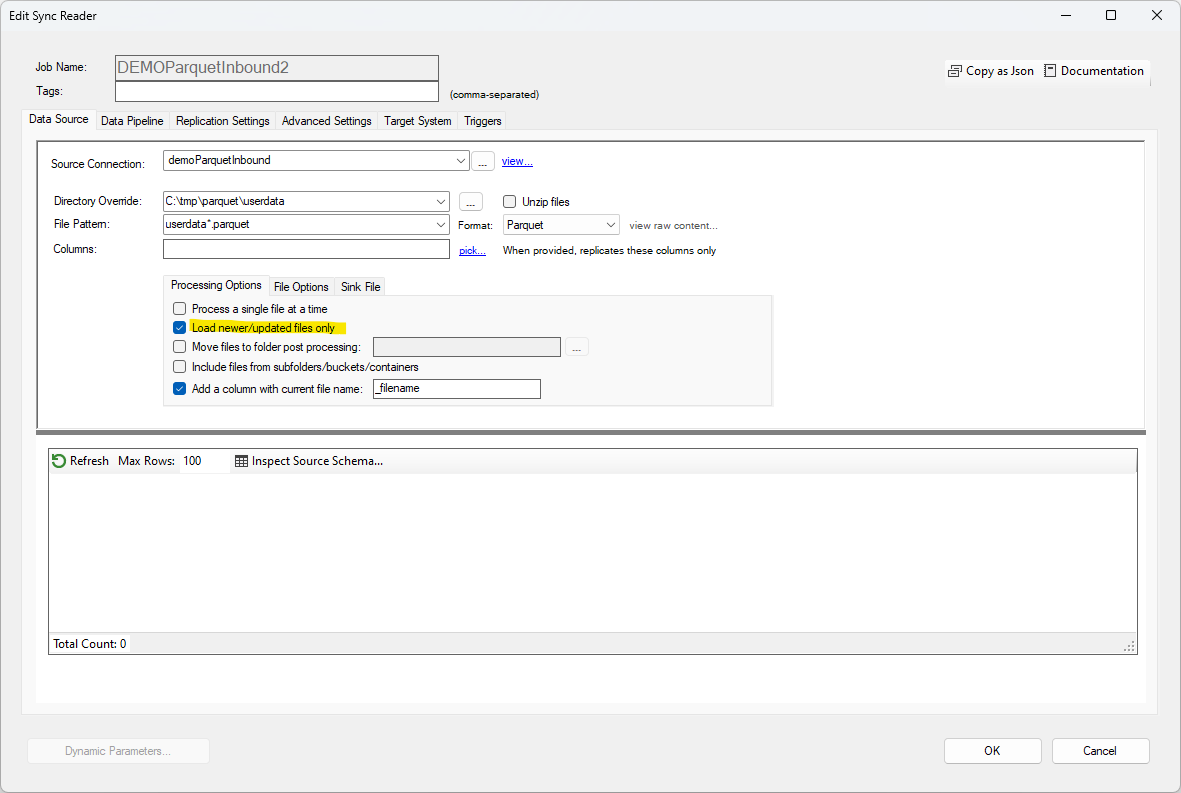
Drive sources include the option to only use the most recently created or updated files, based on their system dates.
Alternatively, drive sources provide the ability to move files that were successfully processed in a sub-folder,
enabling a messaging-style forward-only pipeline that does not rely on system dates.
The option to filter files based on their system date is available across all drives, including: AWS S3 Buckets, Azure Containers,
Google Cloud Drives, FTP sites, and folders.
To enable high watermark tracking on a drive source, select Load newer/updated files only. By default, this option will
treat all available files as a single set with a single high watermark value for all files regardless of the file name.
To track high watermark values separately for each file name, check the Keep separate high watermark values.
Big Data / NoSQL Source
High watermark handling is supported for Big Data / NoSQL sources using the @highwatermark and @highwatermarknull
parameters as explained in the Database Source section above.
Messaging Source
High watermark handling is not supported for Messaging sources.