Inline CDC
This component is a light-weight inline synthetic change data capture that can be used to detect changes in the data over time. While DataZen offers a simple, built-in mechanism to filter unchanged records when reading from a source system, you may need the ability to also apply an inline change capture on the target before applying your changes. Although this component can be both for read and write data pipelines, the primary use case is specific to write data pipelines.
Unline the built-in change capture provided by DataZen, this component externalizes the state table that holds information about the last known state of the target data. In other words, administrators can manually modify this state table if needed.
This is component provides access to an advanced operation and requires a solid understanding of change data capture concepts.
This component requires the use of a SQL Server database in order to perform the inline CDC. The database can be cloud-hosted, including AWS RDS for SQL Server and Azure SQL Database.
Support for Tooling
Because this component provides a custom change capture tracking mechianism, options related to Change Data Capture in DataZen Manager will not apply. For example, the option to Reinitialize will not be available for the inline CDC operation. Other limitations may apply.
Configuration
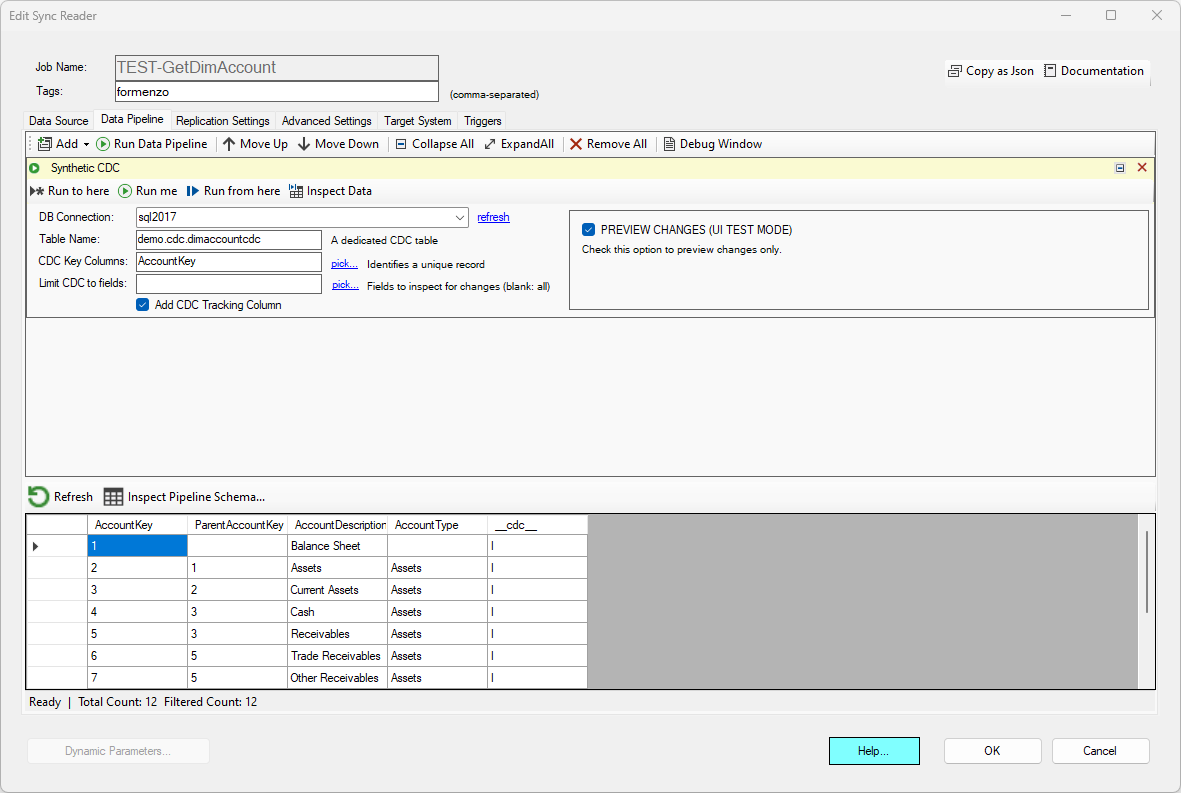
After specifying a database connection to use, enter a CDC table name which will store the last known state of the target records. This table name must be static; using Job Runtime Variables or DataZen functions is not supported. For example, name your CDC table
demo.cdc.dimaccountCDCIf the table doesn't exist yet, it will be created automatically.
Then specify a list of key columns. These columns help identify a unique record. When using more than one field, separate them with a comma. For example:
AccountKeyOptionally, you can check the Add CDC Tracking Column option; when checked, the
__cdc__ field will automatically be added
to indicate whether a record will be I (inserted) or U (updated). This field can be useful if you need to craft different scripts
based on inserted or updated records.
This component doesn't support the identification of deleted records.
State Table Only
The CDC tracking table is nothing more than a state table based on the information it has coming from the source system. The tracking table will be updated as soon as this component completes, whether or not the entire pipeline succeeds. In other words, when using this component, it is up to you to handle retry logic along with any rollback procedures based on the finaly job outcome. For this reason, this component should be used for specific scenarios in which you need a way to identify changes on the fly with the understanding that the state may deviate over time if the data pipeline is not crafted carefully.
Changing Key Columns
The first time you specify CDC Key Columns, the CDC tracking table will be created with the key columns as requested. If you change the
key columns later, an error will be thrown if the tracking table contains data. If you would like to change the CDC key columns after
any data has been saved in it, you will need to manually drop the CDC tracking table first. This is to ensure the CDC tracking table is
not destroyed accidentally.
If however, the CDC tracking table doesn't have yet any data in it, you can modify the CDC Key columns at will. If you get a warning,
simply try again.
Preview Changes
By default, the data pipeline will executed this component in preview mode. In this mode, the component will use the CDC state table in its current state, but it will not change the CDC state of the record. In other words, it performs the synthetic CDC operation but does not commit the results. If the CDC tracking table does not exist, it will be created automatically the first time this component is tested.
To force the component to commit the actual CDC operation to the state table, uncheck the PREVIEW CHANGES option; a warning will become visible indicating that this component will change state records if it is run from the manager application.
CDC Tracking Table
When using this component, the CDC Tracking table is maintained by your administrator. The tracking table will contain the following fields:
| Column Name | Description |
|---|---|
| Key Columns | One or more columns for each Key Column provided (ex: AccountKey) |
| __enzo_idcols_hashbytes | The hash of all CDC Key Column values combined |
| __enzo_created | The date/time when this record was first added |
| __enzo_updated | The date/time when this record was last modified |
| __enzo_hashbytes | The hash of all the fields on the row, excluding the key columns |
| __enzo_status | When 'I' the record is new and must be insterted in the target system; when 'U', the record was modified and must be updated in the target system; if null, the record is unchanged. |
Example 1
In this example, the target pipeline is processing incoming changes from the source system. Since this is the first time the target pipeline is executed, the target CDC tracking table is empty and all records are assumed to be missing from the target system. This inline Synthetic CDC doesn't actually check against the target system whether the records do exist or not; this is up to the administrator to decide how to best handle this tracking table.
Example 2
Let's assume that the target system actually has all the records already, and we just want to initialize the CDC tracking table. Uncheck the PREVIEW CHANGES option, and run the data pipeline. Once completed, the data pipeline output will be empty; that's because all the tracking records are now in the CDC table. Running this command will display the data in the tracking table:
SELECT * FROM demo.cdc.dimaccountCDC