Pipeline Jobs: Overview
A Pipeline Job, also simply called a Job, is usually made of two parts: a read operation, and a write operation. However, depending on the desired integration pattern a number of permutations and variations exist.The read and write operations can exist separately, or be combined. When combined, they are referred to as Direct Jobs. Other more specialized jobs also exist.
Jobs can be classified as follows:
- Job Reader: A job that reads from a database, drive/FTP (files), HTTP/S endpoint, or Big Data table
- Job Writer: A job that writes to a database, drive/FTP (files), HTTP/S endpoint, or Big Data table, and may act as a webhook
- Direct Job: A job that combines a Job Reader and Job Writer into one
- Dynamic Job: A one-time job (reader, writer, or direct) created programmatically with no history and no UI support
- Messaging Consumer: A Job Reader that consumes messages from a queuing platform and optionally forwards them to a target system
- Passthrough Consumer A special Direct job acting as a Messaging Consumer that pushes messages into another queuing platform directly with automatic metadata mapping/forwarding
In its simplest form, a job pipeline reads data from a source system and sends the data to a target system. However, you can easily forward the same data to multiple systems (multicasting) by creating multiple job writers. The only requirement for multicasting changes to multiple systems successfully is to create job writers and ensure its Source Job Name setting uses the original Job Reader name that creates change logs.
Pipeline Processing
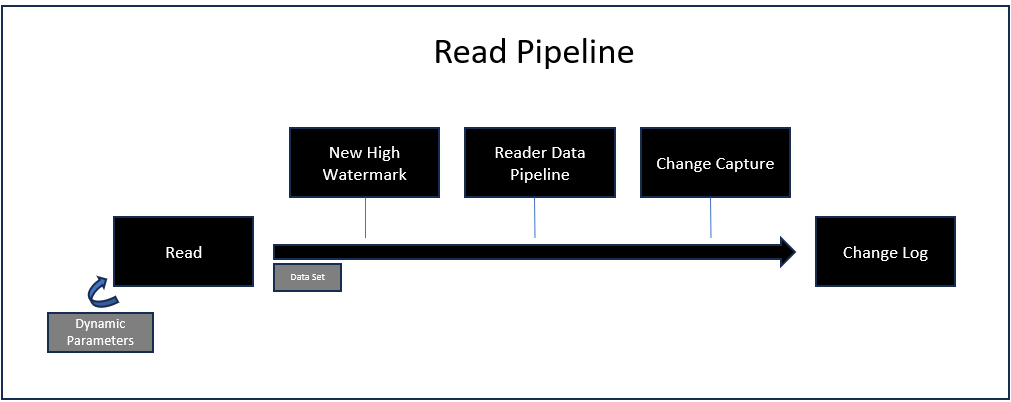
Read Pipeline
Job Readers (including Direct jobs and Messaging Consumers) implement the same ingestion pattern. In all cases, the Read pipeline is a proactive pull of data against a source system. The purpose of the Read Pipeline is to capture data and create a Change Log. The following steps take place during the read pipeline:
- Read: Connects to a source system and read data; HTTP/S job readers also support dynamic parameters that can call the same HTTP endpoint multiple times; if a high watermark exists, and the source system understands it, it is used in this step to limit the number of records returned; the incoming data is always turned into a data set at this point (when raw data is captured from the source, the data set is returned as a single row with the payload and additional metadata); depending on the source system, a secondary call may be required when capturing deleted records.
- High Watermark: If a high watermark is defined, the new high watermark value is calculated in this step, before the execution of the data pipeline; depending on the source system and the strategy used to identify deleted records, a secondary high watermark may be tracked for deleted record identification.
- Data Pipeline: If defined, the data returned by the source system is processed at this point; when Synthetic CDC is engaged, only the upsert stream of data goes through the data pipeline; the deleted stream is stored as-is as it normally only contains key identifiers.
- Change Capture: If CDC Keys have been defined, the Synthetic Change Capture engine is triggered; this could result in the elimination of some, or all, incoming records. Capturing deleted records is optional, but depends on first defining the CDC Keys.
- Change Log: If any data is still available at this stage, a change log is created with two separate internal streams: an upsert and a delete stream; the change log contains additional information such as metadata, schema, and optionally signature information; the change log may also optionally be encrypted; no change log is created if the incoming data set has no records.
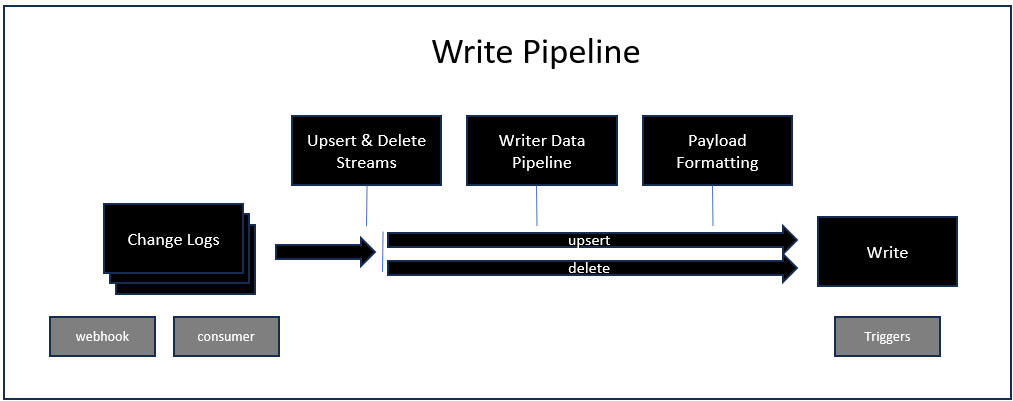
Write Pipeline
Job Writers (including the writer of a Direct Job) start when a change log is available or when a replay is requested. When a webhook exists on a job writer, a change log is created with the data received from the webhook after processing the writer data pipeline. In all cases, the job writer must be enabled to start and a change log must be available.
- Change Log: A change log is required to start the writer pipeline. By convention, the name of the change log file contains two pieces of information: the name of the job reader that created the log and the timestamp of the change log when it was created. This ensures that only the desired change logs are processed by the job writer, in sequence. The change log also contains the CDC Keys used, if any, when capturing the data.
- Data Streams: Each change log contains two streams of data for new/modified data and deleted records. If the change log was created from a source job without CDC Keys, only the first stream will contain data.
- Writer Data Pipeline: The Job Writer can have its own data pipeline, independently of the job reader that created the change log. Unlike the reader pipeline, the writer pipeline will execute for both data streams.
- Payload Formatting: Before sending data to the target system, the job writer performs a few additional steps that vary based on the target system, including: mini-batching, data shaping, partitioning the target object, and formatting the payload.
- Write: The write operation may be executed multiple times depending on the batch option available for the selected target system. Additional options are available to change the default behavior of the write pipeline depending on the outcome of this step, including retry and dead letter options.
Create a Job
To create a new job, select the desired DataZen Agent on the left bar in DataZen Manager, and click on the New dropdown menu. Your available options may vary based on the agent (Cloud-Hosted vs. Self-Hosted) and your license.
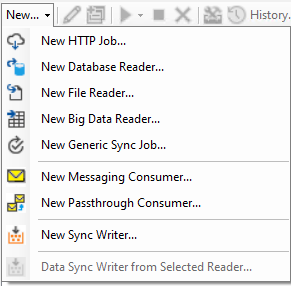
The Data Sync Writer from Selected Reader helps you create Job Writers more quickly when the Job Reader it depends on is already selected from the list of jobs.
Cloud agents do not support all job types. Unsupported job types will be grayed out.
Start a Job
Jobs can be started manually, automatically, or programmatically. Job Writers that also act as a webhook start as soon as an incoming HTTP/S request has been received.
A job will not run if it is currently disabled or if it is already running.
Messaging Consumer jobs do not run on a schedule; their listener are either in an enabled or disabled status. To stop a listener, you must disable it; and to start it, reenable it.
Start a job manually
Even if a job is scheduled to start automatically, you can start it manually as long as it is not already running. Select the desired job and click on the Start icon (or right-click the job to show a context menu with similar options).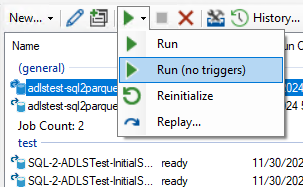 The following options are available:
The following options are available:
- Run: Start the job as soon as possible.
- Run (no triggers): Run the job, but do not start job triggers.
- Reinitialize: Read all available source records, and optionally recreate an initial change log
- Replay Replay change logs from a specific point in time, or choose a single change log to replay against the target
Start a job on a schedule
To schedule a job to execute on a specific schedule, edit the job and choose a schedule in the Replication Settings tab. Job schedules use CRON specifications.
The following options are available:
- Run: Start the job as soon as possible.
- Run (no triggers): Run the job, but do not start job triggers.
- Reinitialize: Read all available source records, and optionally recreate an initial change log
- Replay Replay change logs from a specific point in time, or choose a single change log to replay against the target
Start a job on a trigger
Most jobs can also be started when another job completes, as a trigger. See the Triggers section for more information.Start a job programmatically
Most jobs can also be started programmatically, using a Powershell command or a direct HTTP/S call to the Agent.Cloud agents jobs can be started programmatically too but require a specific authentication header; your Enzo online account must be enabled for such access. Please contact support for more information.
Start a dynamic job
You can start a job dynamically, without creating the job first, using a Powershell command or a direct HTTP/S call to the Agent.Cloud agents do not support dynamic jobs
Pushing data (webhook)
While most jobs read data from a source system proactively, you can also push data programmatically by sending a JSON, XML, or CSV payload using the DataZen API by calling the /job/push endpoint. See the Webhook section for more informationCloud agents require a specific authentication header; your Enzo online account must be enabled for such access. Please contact support for more information.
Job Name and Sync Files
The Job Name is used to tie Job Readers and Job Writers when created separately. The name of the Sync File that holds the change log for the source data starts with the Job Reader Name. When creating a Job Writer, you specify the name of the Job Reader that was used to create the Sync File so that the writer knows which files to read.