Synthetic CDC
DataZen has a built-in data differential engine that can quickly identify net changes of data sources over
time. This feature is designed to extract changes from source systems that do not offer a change stream
or that do not have a mechanism to keep a high watermark pointer.
DataZen uses its internal synthetic CDC identification logic automatically based on the type of
source system and options selected for the job. Generally speaking, this differential engine
tracks the signature of source records in an internal staging database and compares them over
time as records are being extracted from the source system.
The synthetic CDC engine is bypassed in the following scenarios:
- the source system is a CDC data source itself (such as SQL Server CDC or Change Tracking)
- the job reader does not specify CDC Key Columns
How to Engage CDC
To engage the automatic Synthetic CDC in a Job Reader, use the CDC Key Columns setting
under the Replication Settings tab. One or more columns can be specified.
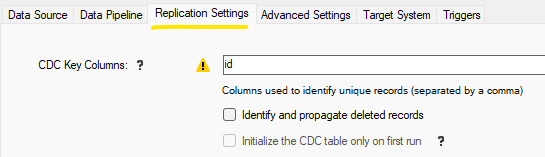
Changing these Key Columns after a job has run once may cause unpredictable results. You can force a full resync operation to recreate the internal CDC table.
Limit CDC Fields
By default, all fields from the source data pipeline are observed during the CDC operation; if any field changed
the record will be marked as modified. In certain scenarios, it may be necessary to only inspect a few fields for
changes. This allows you to control the fields that the CDC will observe for changes.
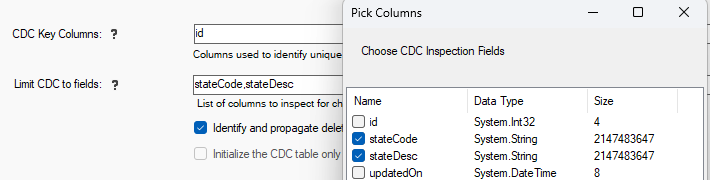
Changing these Key Columns after a job has run once may cause unpredictable results. You can force a full resync operation to recreate the internal CDC table.
How to Disengage CDC
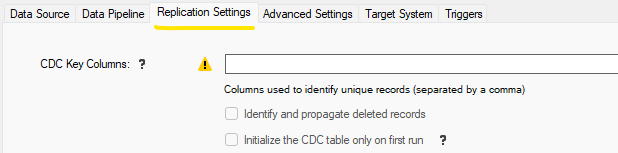
To disengage the automatic Synthetic CDC in a Job Reader, clear the CDC Key Columns setting
under the Replication Settings tab.
Ignoring Duplicate Records from the Source System
In rare cases, source systems may return duplicate records over time for key values that are supposed to be unique, either due to paging requests
that overlap slightly or as a result of an issue with the source system itself returning duplicate records unexpectedly. Since engaging CDC
results in identifying unique records by design, processing duplicate records will throw an error (ERR-STG-005) and the data pipeline will
stop with an error.
You can use the Ignore duplicate records from source system option to discard duplicate records extracted from the source system.
Doing so will process the first record for a given set of CDC Key Columns and discard any additional records from the source data during the pipeline execution.
Using this option may cause performance degredation when dealing with large recordsets. In addition, if the duplicate records as identified by their unique key columns contain different data in other colums, data loss may occur. As a result, using this option should be used when you have no other practical way to eliminate the undesired duplicate records.
Unless special measures are taken, a Job Reader will create a Change Log that contains all the source records, which is also referred to as an Initial Sync file. A Resync operation also creates a Change Log with a complete set of records from the source system.
When the Synthetic CDC option is disengaged, all records detected from the source system are forwarded to the Sync File, unless the Job Reader has a High Watermark defined (Timestamp, DateTime or a Long value).
CDC State Table
When one or more Key Columns are specified in a Job Reader, the data read from the key columns are hashed and stored seperately in a database table to keep state information.
The CDC state table is used to detect any changes made to the source records, including any data updates, column changes (including data type). Although this state table contains limited information (mostly hash values), the number of records to be stored in this table may be very large depending on the source system.
The Synthetic CDC engine is capable of identifying "net" changes between two time intervals, including deleted records when the option is selected. The outcome of the differential analysis performed between two time intervals is stored in the Change Log.
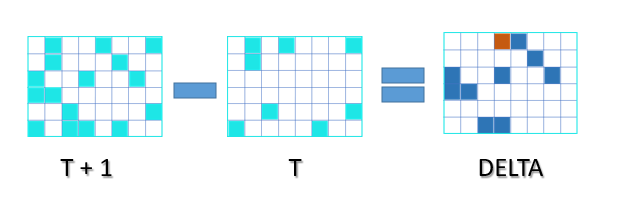
Because DataZen calculates "net" changes only, the identification of an inserted versus updated record may not always be possible. As a result, the Change Log contains two types of changes: upserted and deleted. It is up to the target system to perform an insert operation if the record is missing, or an update operation if the record is already present.