Debugging a Data Pipeline
Debugging a data pipeline may be necessary when you are building a new data pipeline or experiencing an unexpected issue on an existing pipeline. Regardless of whether you are trying to debug a source pipeline or a target pipeline, you need to have data available so you can test pipeline components.
- For source pipelines on a Job Reader, you first need to run the "preview" operation so that the pipeline has some data to start with
- For target pipelines on a Direct Job, you first need to run the "preview" operation on the source and run the source pipeline completely so that the target pipeline has some data to start with
- For Job Writers pipelines, including webhooks, you will need to load a change log or have some sample data available first
Once some data is available for processing, two support windows are available: Debug Window and Data Inspection.
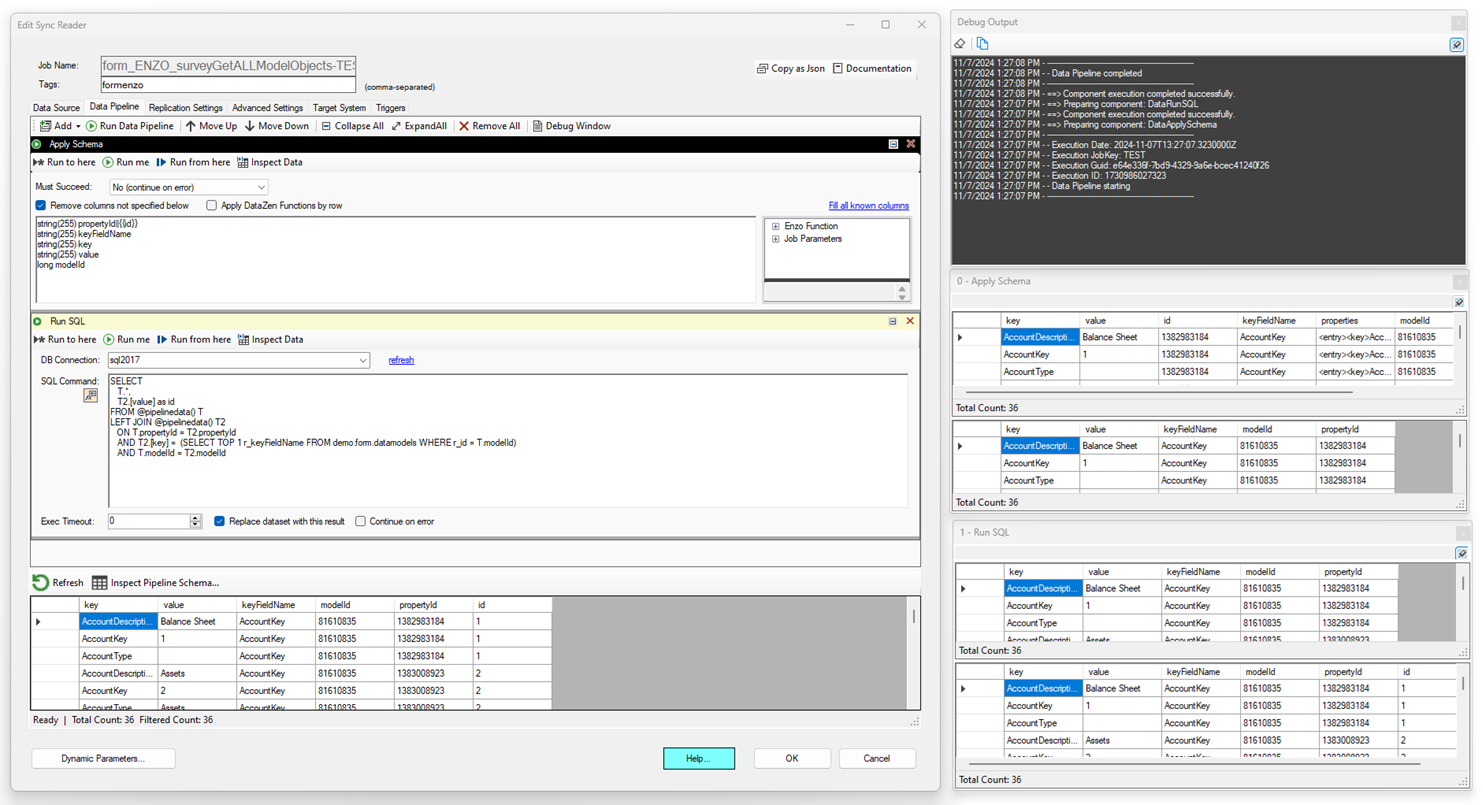
Debug Window
This window is a pipeline-level output of all the components. When a pipeline starts, its execution variables are displayed, including the Execution Date, Execution ID (same as the date, in millisecond Epoch format), and the Execution GUID. These three values will be different every time the job starts. When running in debug mode, the JobKey will always be 'TEST'.
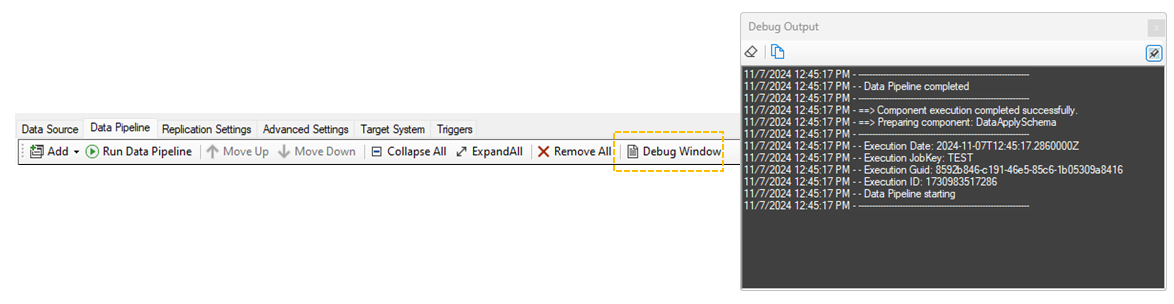
Data Inspection
This window is a component-specific data inspection tool showing the data before entering and after leaving the component. This window may show an empty data set if you haven't executed the data pipeline up to this point.
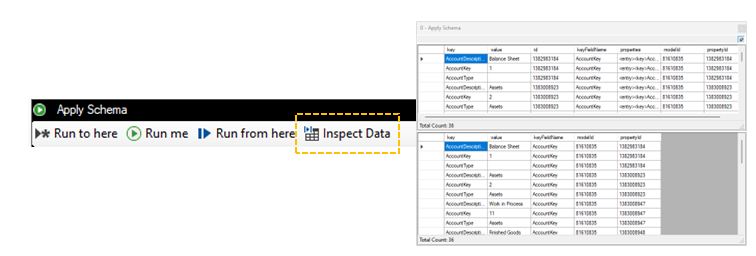
Executing a Data Pipeline
You can run a data pipeline from top to bottom by clicking on the Run Data Pipeline button, or execute each component one at a time, progressively. Either way, you can first position the desired debugging windows and pin them so they stay on top; you will then see the components execute progressively.
In this example, data is first retrieved from an HTTP/S endpoint on the source tab (not shown) and was already converted into rows and columns. The first component reduces the number of fields and enforces a specific schema, and the second component executes a SQL command on the fly using the pipeline dataset to extract which the field that should be used as a unique identifier in the target system (the id field). Note the use of the @pipelinedata() operator in the Run SQL component, twice, to join the incoming dataset on itself.