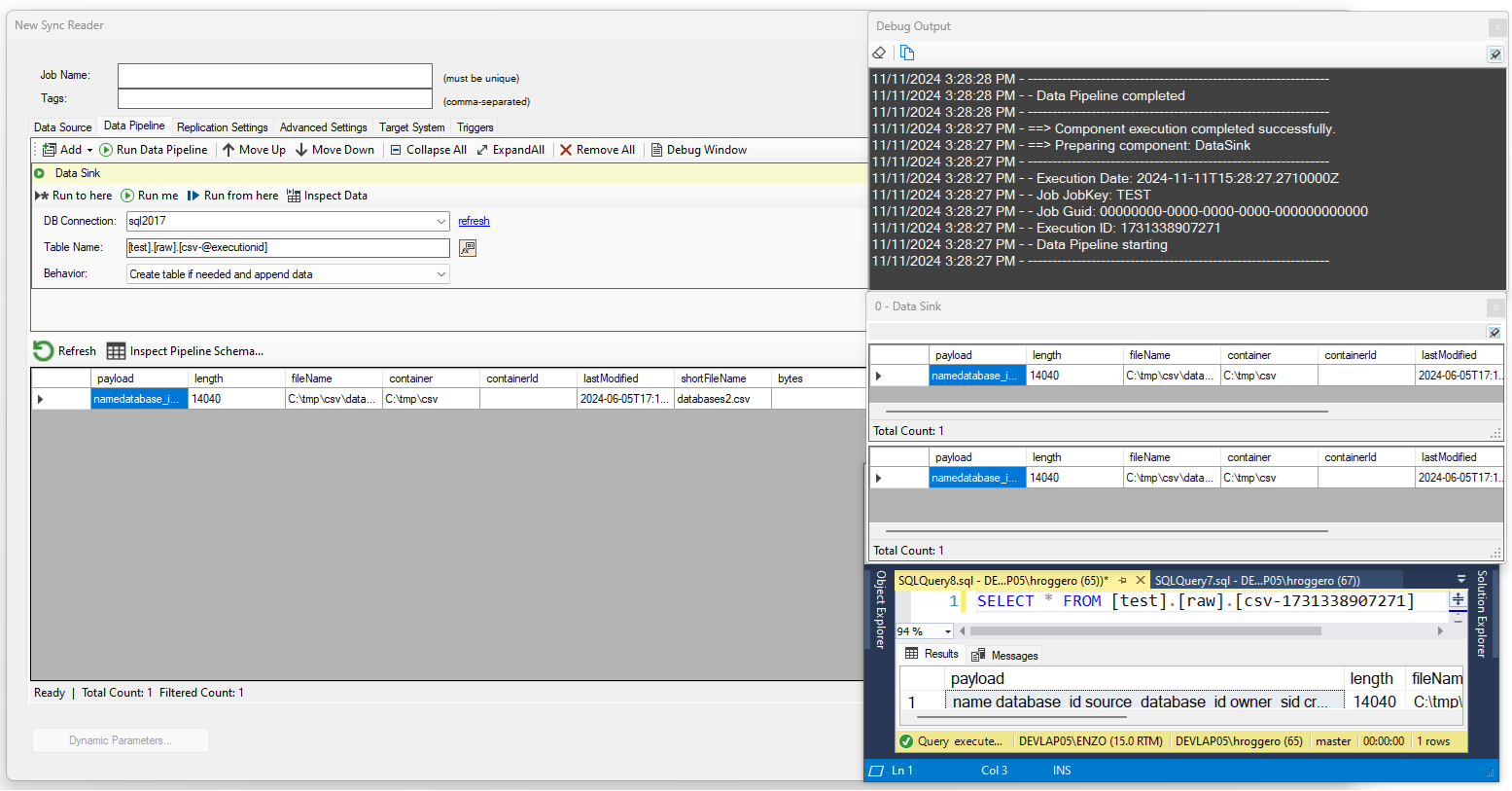
Sink to SQL Server
Use this component to dump the current data pipeline data set into a SQL Server database table. This component does not change the data pipeline data set. This can be useful in the following scenarios:
- Debugging: dump the current data pipeline data for debugging or troubleshooting purposes
- Raw Store: dump the result of the previous component, such as the payload of an HTTP call, for historical or downstream processing
- Checkpoint: dump the current data pipeline, continue processing, and merge back the results later in the same pipeline
This component requires the use of a SQL Server database in order to sink its data. The database can be cloud-hosted, including AWS RDS for SQL Server and Azure SQL Database.
Select a SQL Server database connection from the dropdown list of connections, and optionally enter a table name. The table name
can be a three-part table, including a database name, schema name, and table name. You can also use DataZen functions to name this table and
job runtime variables. For example, to tie the table name to the current execution id, you could name your table like this:
[raw].[tmp-@executionid]. If the table name is not provided, a random table name will be created; while this option is supported,
using a deterministic name for the table makes it easier to use it within the data pipeline.
Three behaviors are supported:
- Create and Append: Create the table if it doesn't exist and append the data to it; using this option will continuously load new rows in the table as the job is executed over time. The schema should not change over time for this option to work.
- Truncate first: Create the table if it doesn't exist, and truncate it on every execution of this component before sinking the data; when using this option, previously saved data will be lost. Use this option if the schema does not change over time.
- Drop and Recreate: Drop the table if it exists then recreate it before sinking the data; when using this option, previously saved data will be lost. Use this option if the schema can change over time.
In this example, we are sinking the result of reading from a flat file into a database table with the current @executionId.
as part of the table name: [test].[raw].[csv-@executionid] .Using the @executionId as part of the name ensures the table is unique, and makes it easy to query in a downstream component
if needed.