Job Writer: Big Data
To send data to a Big Data or NO-SQL platform, select a Big Data target system. Big Data targets have additional field-mapping options as explained below.
At this time, only Google BigQuery and Azure CosmosDB are supported as Big Data connections.
Example 1: CosmosDB - Mapping
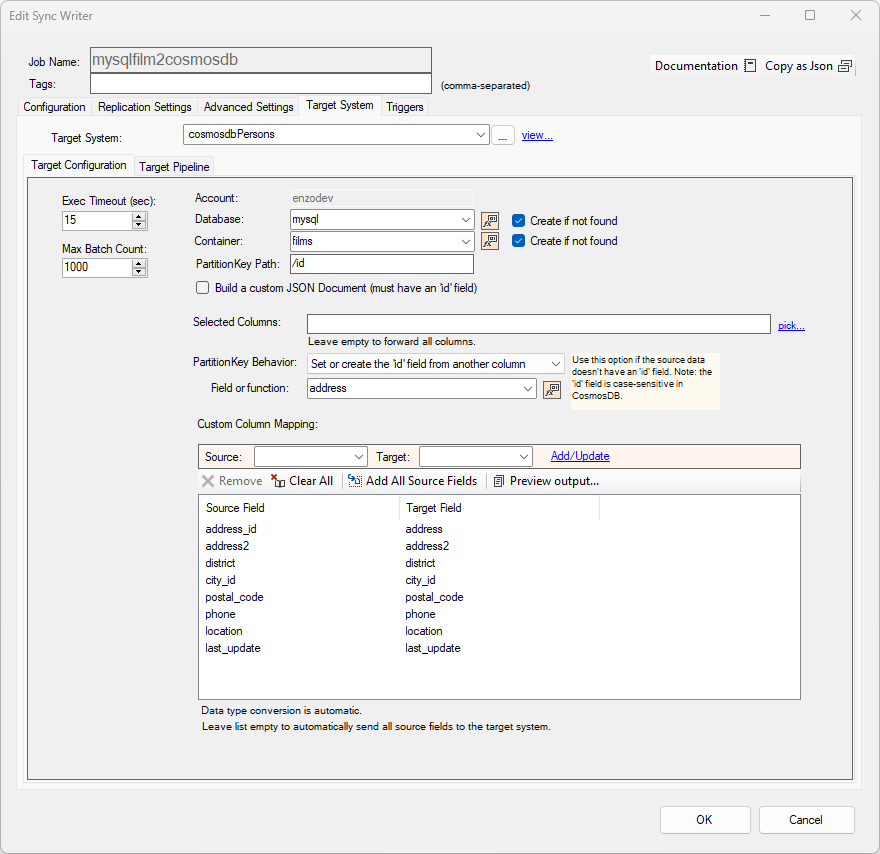
In this example, the settings use a CosmosDB target system. The Database, Container and PartitionKey Path values are set as needed. This example shows you how to build the payload using the source field names automatically. These fields can use DataZen Functions and you can choose to create the Database or Container automatically as needed.
When Selected Columns is left blank, all the columns from the source system are forwarded to the database.
You set the Partition Key (id) as a random Guid, from an existing source 'id' field, or by using the value of another field.
The following characters are not allowed for field names in a CosmosDB table:
+,.[]!"#$%&\()*/:;<>?@'^`{}|~
Field names cannot start with an underscore (_) or the minus symbol (-)
Example 2: CosmosDB - Custom Payload
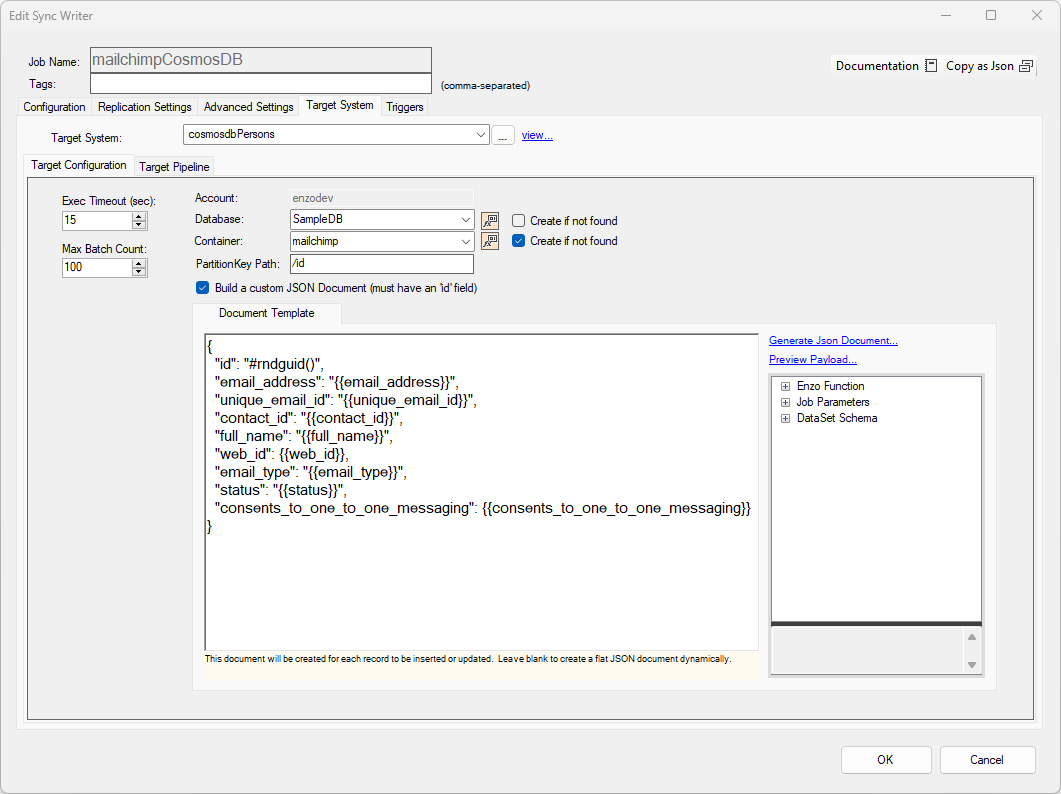
This example shows you how to build a custom payload using the source field names, and setting the id field to a random guid value. This option allows you to build complex JSON documents.
Example 3: Google BigQuery
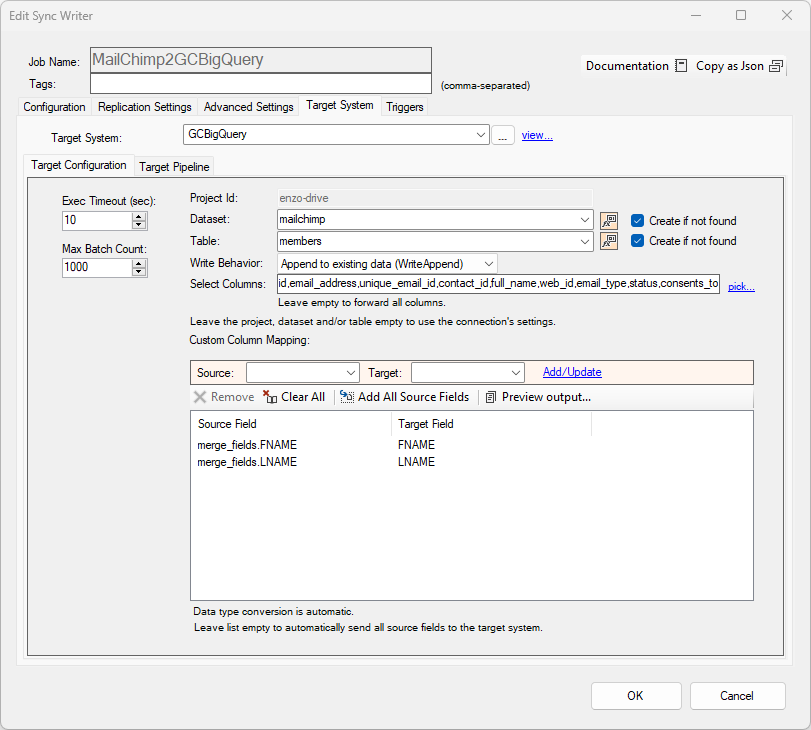
In this example, the settings use a Google BigQuery target system. The DataSet and Table values are set as needed. This target system requires you to map source columns to target columns. You can choose to create the DataSet or Table automatically as needed.
When Selected Columns is left blank, all the columns from the source system are forwarded to the database.
Data-type conversion is automatic.
The following characters are not allowed for field names in a BigQuery table:
.|-@!$%^&*=+
Field names cannot exceed 300 characters