Job Reader: Big Data
Use a Big Data Job Reader when reading from Azure CosmosDB or Google Cloud BigQuery system. These source platforms offer specific settings tailored to their unique characteristics.
CosmosDB Reader
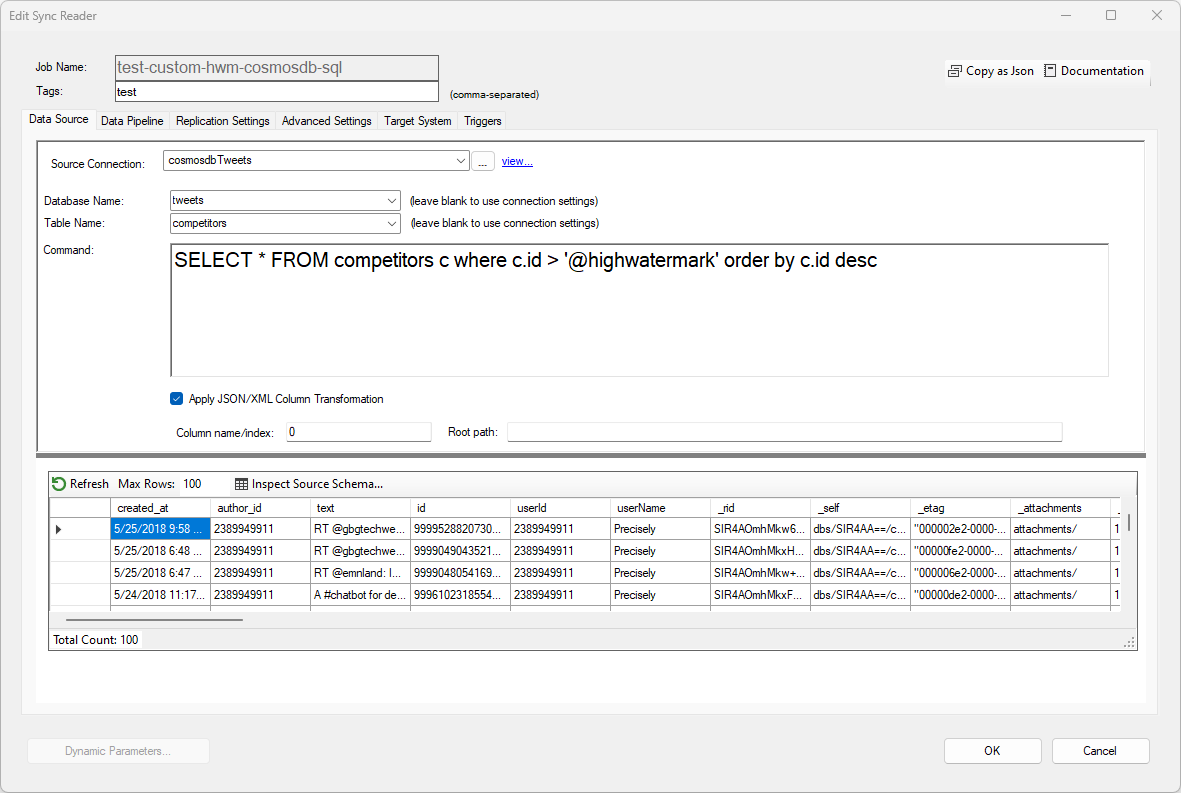
To read data from a CosmosDB database, select the desired Connection String and enter the desired SQL command. When reading from a NoSQL data source, use the Apply JSON/XML Column Transformation option to convert the data into rows and columns if desired.
A Database Name and Table is required, although DataZen can use the default settings specified by the Connection String. Only a CosmosDB SQL endpoint is supported.
This reader supports high watermark when using the @highwatermark token directly as part
of the SQL command. The first time the job runs, or when a resync is performed, the high watermark value
will be an empty string.
BigQuery Reader
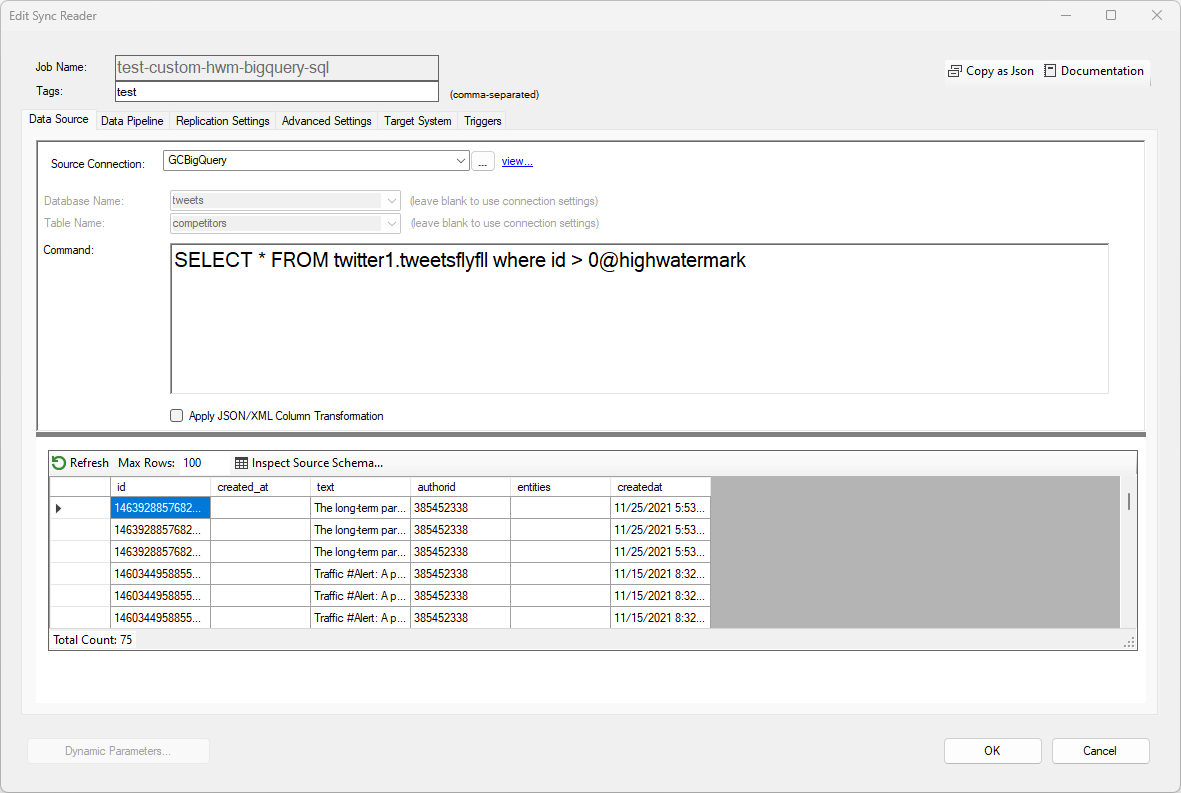
To read data from a BigQuery table, select a BigQuery connection and enter the desired SQL command. By default, data returned by BigQuery is already provided as rows and columns.
This reader supports high watermark when using the @highwatermark token directly as part
of the SQL command. The first time the job runs, or when a resync is performed, the high watermark value
will be an empty string.
TIP: If the high watermark field is numeric, you can prepend the token with a 0, for example:
id > 0@highwatermark.
Since the first time the query runs the mark is an empty string, the query will return
all records in this example.