Job Writer: HTTP/S
DataZen allows you to forward data to an HTTP/S endpoint. Select an existing HTTP/s connection to see the available HTTP/S target options. You can specify two separate HTTP requests (an Upsert and a Delete operation). The HTTP Upsert and Delete operations have a totally different set of configuration options, including the Continue On Error and Finalization Options settings.
Some HTTP/S endpoints require a separate call for Add and Update calls. This may require you to create an additional Job Writer when the HTTP Verb is different (PUT vs. POST). However, if the Verb is the same and the body is the only modification required, you may use the Target Data Pipeline to craft the payload first.
When building an HTTP/S request, specify the HTTP Verb, the Content-Type and the HTTP URI to call. The Max Batch Count controls how many records are included when building the payload. If you use one of the array functions (@concatjson for example), the array will contain up to Max Batch Count entries.
You can use DataZen functions to format the HTTP URI and the payload HTTP Payload being sent. For example, if the HTTP URI is a REST endpoint and the URI expects two variables (list_id and contact_id) found as part of the data, the URI would look like this:
/lists/{{list_id}}/members/{{contact_id}}
When using a REST-like operation as described above, the Batch Count setting is ignored.
Continue On Error
The Continue On Error option allows you to control whether the job should continue to
process additional batches, if any, when a specific (or a range of) HTTP error(s) is detected.
In some scenarios, you may want to ignore errors that are thrown when a record already exists.
To configure the job to ignore errors that fall between 400 and 403, type or select 400-403 from
the list:

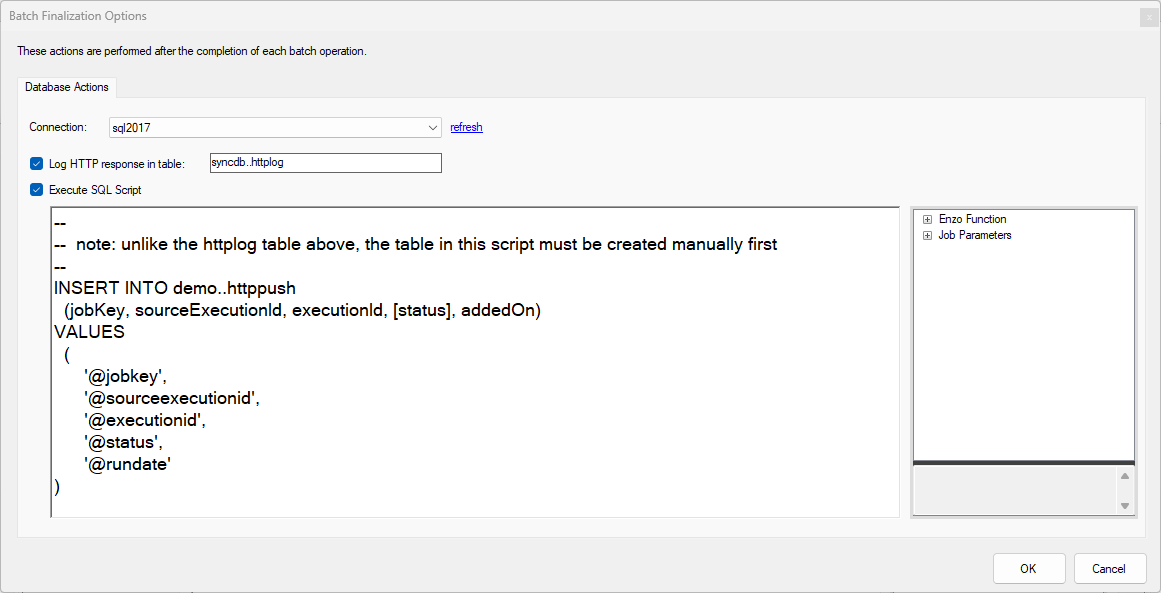
Finalization Options
The Finalization Options settings allow you to save detailed responses from the HTTP
endpoint to a database table and/or optionally execute a custom SQL script.
The log table will be created automatically if it doesn't exist. Multiple target HTTP jobs can
use the same table. The custom SQL script allows you to perform additional logging, or trigger
another database operation.
This script executes every time a batch completes. If the HTTP call is a REST operation, this script
executes for every record processed (1 record per batch).
INSERT INTO demo..httppush
VALUES ('@jobkey', '@sourceexecutionid', '@executionid', '@status', '@rundate')
Max Batch Count
The number of records specified in the Max Batch Count setting functions differently depending on the content of the HTTP payload in the following ways:
| Without Batch Operators | When no batch operator is found in the payload template, the template provided will be used for each record (up to the Max Batch Count value) and appended with a new line-feed to build the actual payload sent |
| With a Batch Operator | When a batch operator is found, the content within the operator will be used as the template for each record using the appropriate separator for the target system |
| @sql_concat() | Assumes the content is a SQL SELECT command and the ; character will be used as the separator for each record |
| @sql_union() | Assumes the content is a SQL command and a UNION operator will be used as the separator for each record |
| @sql_unionall() | Assumes the content is a SQL command and a UNION ALL operator will be used as the separator for each record |
| @concatjson() | Assumes the content is a JSON document and a , will be used as the separator for each record and surrounding curly brackets ({ }) will be added if missing |
| @concatjsonarr() | Assumes the content is a JSON array and a , will be used as the separator for each record and surrounding square brackets ([ ]) will be added if missing |
| @concatxml() | Assumes the content is an XML document and a New Line will be used as the separator for each record |
See the Document Formatting section for more information.
HTTP PUT Example
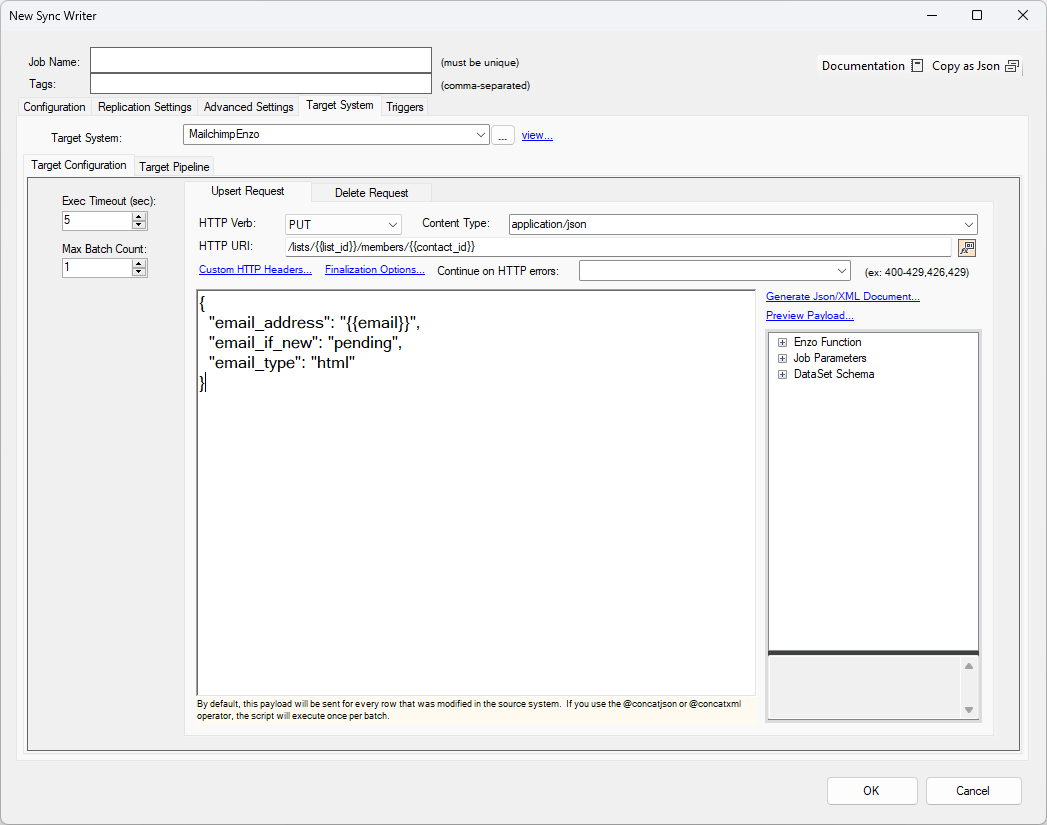
In this example, the source data is sent (one record at a time) to a target endpoint with the root URI specified by the selected Target System. The source data is expected to have the following three columns: list_id, contact_id, and email. The payload is a JSON string.
The Max Batch Count setting is important; since we are building one payload per record, the max count should be set to 1.
Sending a JSON Array
If the target system accepts an array of JSON documents, you can use the Generate JSON/XML Document link to build the array. In this case, the number of items in the array will be controlled by the Max Batch Count setting. Use the @concatjson function to send an array of objects and @concatjsonarr to send an array of values.
[
@concatjson(
{
"email_address": "{{email}}",
"status_if_new": "pending",
"email_type": "html"
})
]
If the target endpoint needs an XML payload, use the @concatxml function instead.
If the target endpoint needs a JSON payload, you may need to flatten string fields using the @singleline() function to ensure the string fits on a single line; JSON documents do not support carriage returns or line feeds.
HTTP POST with SQL Example
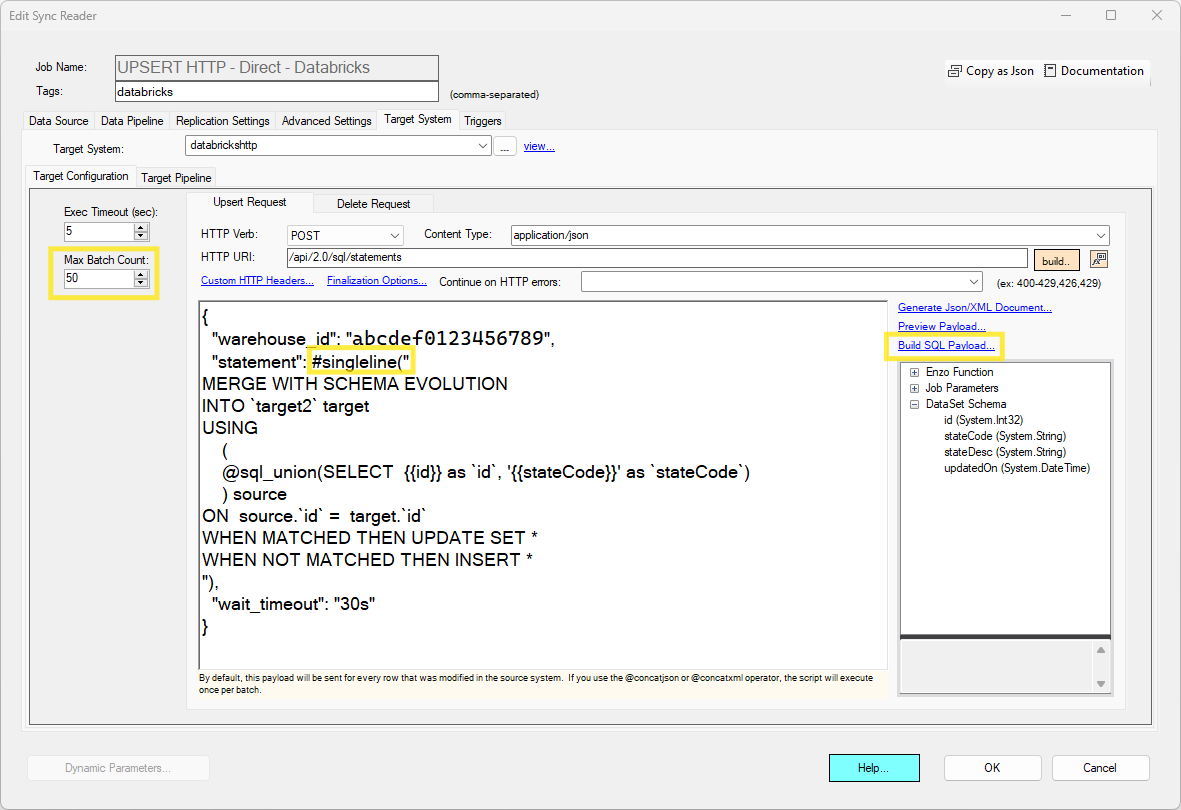
In this example, the source data is sent (50 records at a time) to a Databricks target endpoint with the root URI specified by the selected Target System. The payload follows the Databricks API specification, which requires the warehouse_id value and a statement to execute. Since this is a SQL command that is build over multiple lines, the #singleline() operator is used to flatten the entire SQL script into a single line.
Building the SQL Command
This HTTP payload contains an SQL command which can be difficult to build. In this example, the SQL command was built using the Build SQL Payload screen. See the HTTP SQL Payloads section for more information on how to build this script.