Job Reader: Drive
DataZen allows you to read files (one or more) from Drive Connections, including cloud drives and FTP sites. The following file types are supported:
- CSV: delimited or fixed length files
- JSON: JSON documents
- XML: XML documents
- Parquet: Parquet files
- Raw Text: text file content
- Raw Bytes: binary file content
Depending on the file format, certain options vary.
Settings
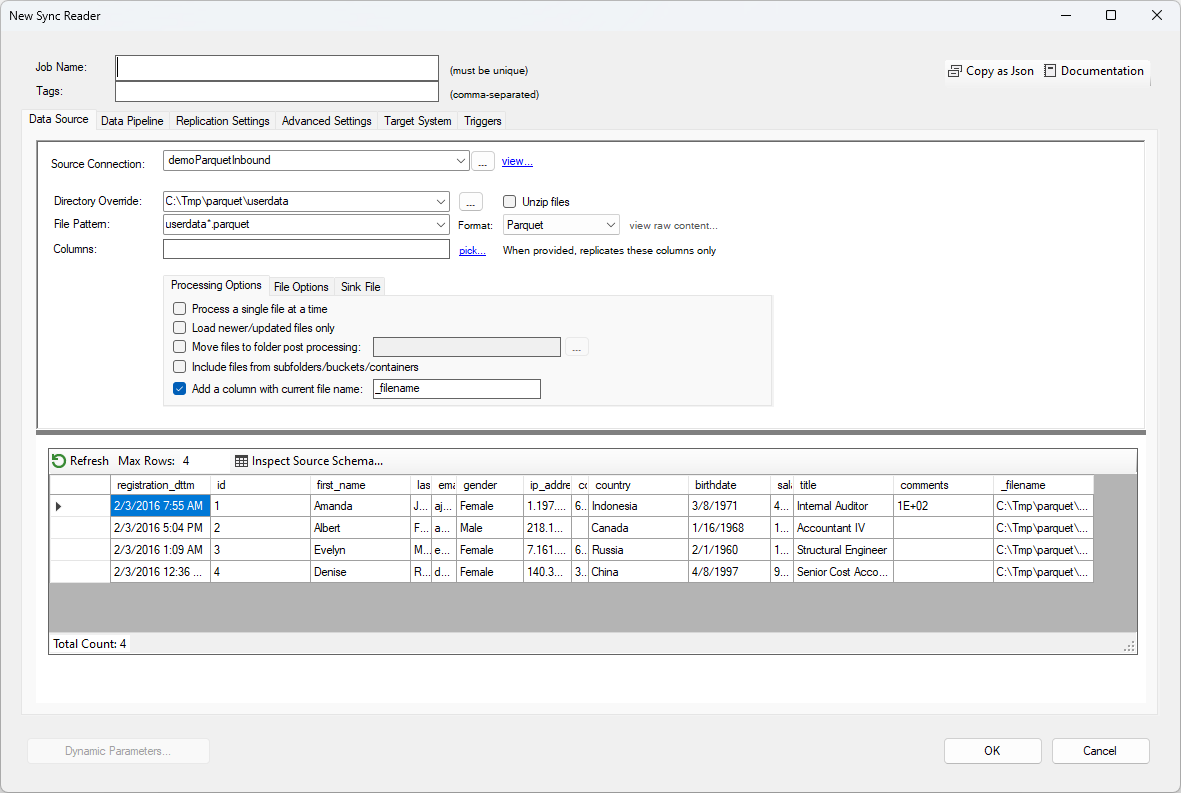
To read from a source file, choose your Drive Connection and optionally override the default directory. Then enter the file pattern to use. This field allows you to use * and ? wildcards to perform the data extraction on multiple files. In this example, any file matching this pattern will be read: userdata*.parquet. You can further limit which columns to read from by listing them in the Columns field.
Although DataZen can attempt to automatically detect the file type provided, certain options are only available when selecting the type from the Format field.
The following options are available for all file types:
- Unzip Files: Check this box if the files should first be unzipped.
- Process single file: if left unchecked, all files are read and assumed to be part of the same data set; the same Execution ID is used as well. This option has an effect on how unique records are treated. Use this option if each file should be processed individually.
- Move files to folder: when selected, files are moved to a different folder after being successfully processed.
- Include files from sub folders: Use this option to walk down the sub-directory structure to find additional files.
- Add Column with file name: Use this option to add a trailing column with the name of the file the current record comes from
File Options
Specific options are provided for JSON, XML, CSV, and Raw file types.
CSV
For CSV file types, the following options are provided:
- Has Header: when checked, the first row will be treated as the file header
- Trim Fields: when checked, field values will be trimmed to remove leading and trailing white spaces
- Delimited File: by default, the selection of the serparator is automatic; you can override it here and enter multiple characters (each character will be treated as a unique separator, ex: |;)
- Fixed Length: by default, the identification of fixed length is automatic; you can override it here, separating expected lengths with a comma
- Comment Tokens: a comma-separated list of strings that identify comments when found at the start of a line
The CSV parser is designed as a memory-optimized forward-only reader allowing you to ingest very large files.
XML/JSON
When a JSON or XML document type is selected, you can apply a Document Path setting that transforms the document into rows and columns. See Document Path for more information.
Raw
The Raw Text or Raw Bytes option allow you to return the list of files in the drive instead of reading the content of the file. This option can be useful when the Data Pipeline is further used to push files as attachment to an HTTP/S endpoint, such as a Machine Learning or AI endpoint.
Sink File
This tab allows you to save the files content into a transient database table in order to keep track of the files that are available for processing. This can be used for troubleshooting purposes, or to further process the content in a Data Pipeline. The database server must be a SQL Server database.
If it already exists, the table specified in this setting is dropped every time the job starts executing. If you need to persist this data permanently, you can use the Data Pipeline to save the records in another table. When previewing the data, you can choose to perform the sink operation or not.