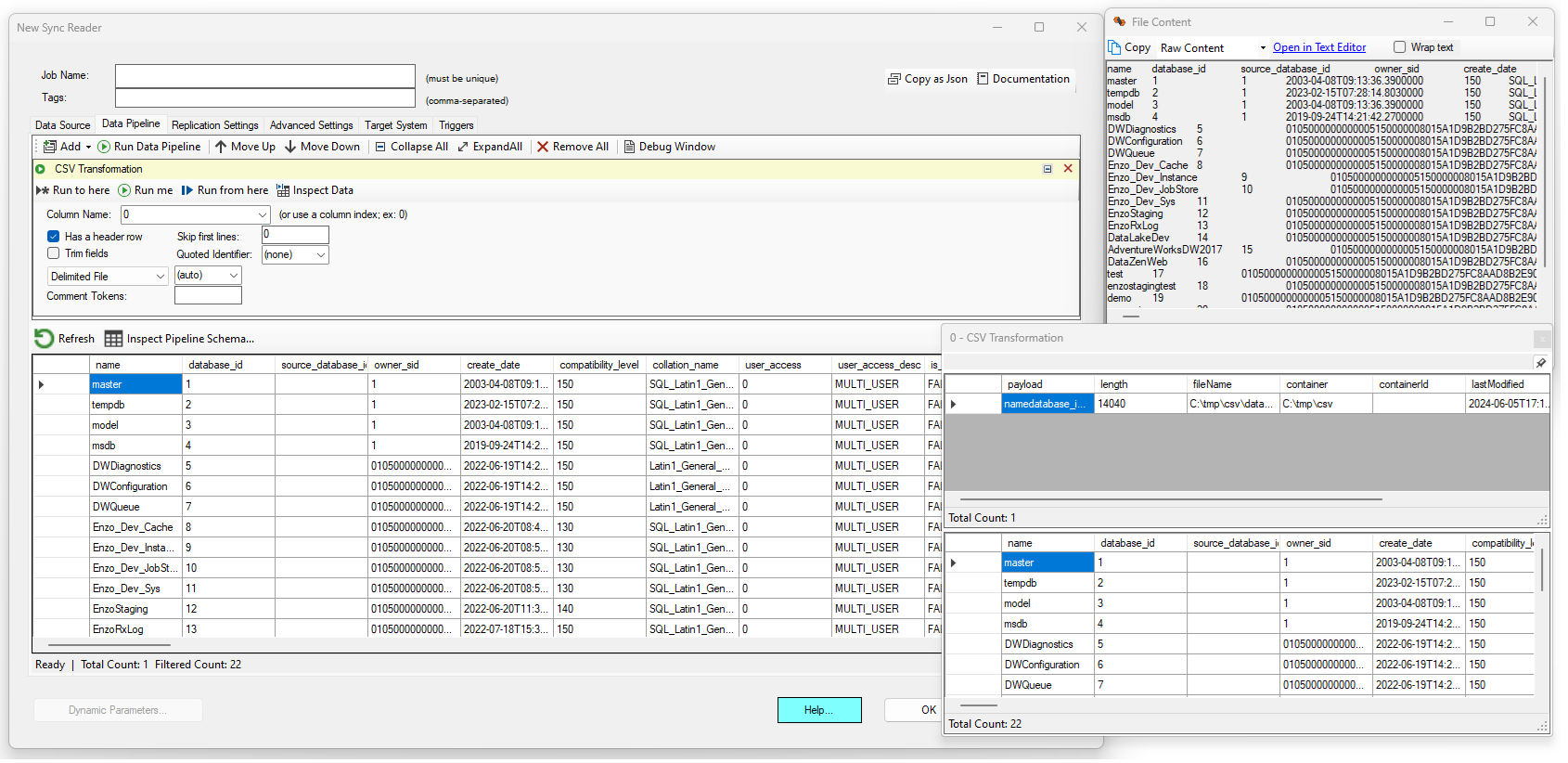
CSV/Flat File to Table
This component allows you to automatically convert a Delimited or Fixed Length document into a data set of rows and columns. This component operates on a column; you can either specify the name of the column or its index. If the pipeline data set contains multiple rows, all the rows will be processed individually and the results will be concatenated into a single output.
If the file has a header line, check the Has a header row option. Use the skip first lines to ignore a set number of lines on top of the file. The Trim Fields option will remove trailing and leading spaces, if any.
Choose a Quoted Identifier if you would like the identifier to be removed automatically, such as surrounding double-quotes.
Choose the Delimited File if the data has a separator between fields. Note that if leave the (auto) option selected,
DataZen will do its best to identify the most likely separator by performing a quick lookup on the first few rows. However, in some
cases, you may need to pick the desired separator when multiple options are possible. In addition, you can list more than one character
separator (for example, you could split all the fields by both a comma and a semi-column: ,;).
Choose the Fixed Length File option when the data is aligned at specific locations. When choosing this option, a position box is displayed
that allows you to specify the list of positions to use separated by a comma. For example, you could enter: 10,25,29,40.
When providing this list of positions, the first position (0) is optional. In addition, you can use relative positions by adding a +
symbol in front of any value: 0,10,20,+5,+1.
Note that providing the list of positions is optional; if left empty, the component will automatically calculate the expected positions
using a quick statistical analysis of the first few rows.
One or more comment tokens can be used to exlude rows from being processed. To specify multiple comment tokens, use a comma between them.
For example: #,--
In this example, the first column (index 0) holds a delimited file (as seen in the File Content window). The delimiter of the file is automatically detected and this file has headers on its first row. After extracting and converting the CSV payload, the original pipeline data set is replaced with the output of this component.