Job Reader: Database
This job extracts data from relational databases using a native driver, an ODBC data source, or an Enzo Server. If the database is SQL Server, the job can also read from Change Tracking or Change Data Capture feeds.
Reading from ODBC data sources is not currently supported by cloud agents.
Using an SQL Command
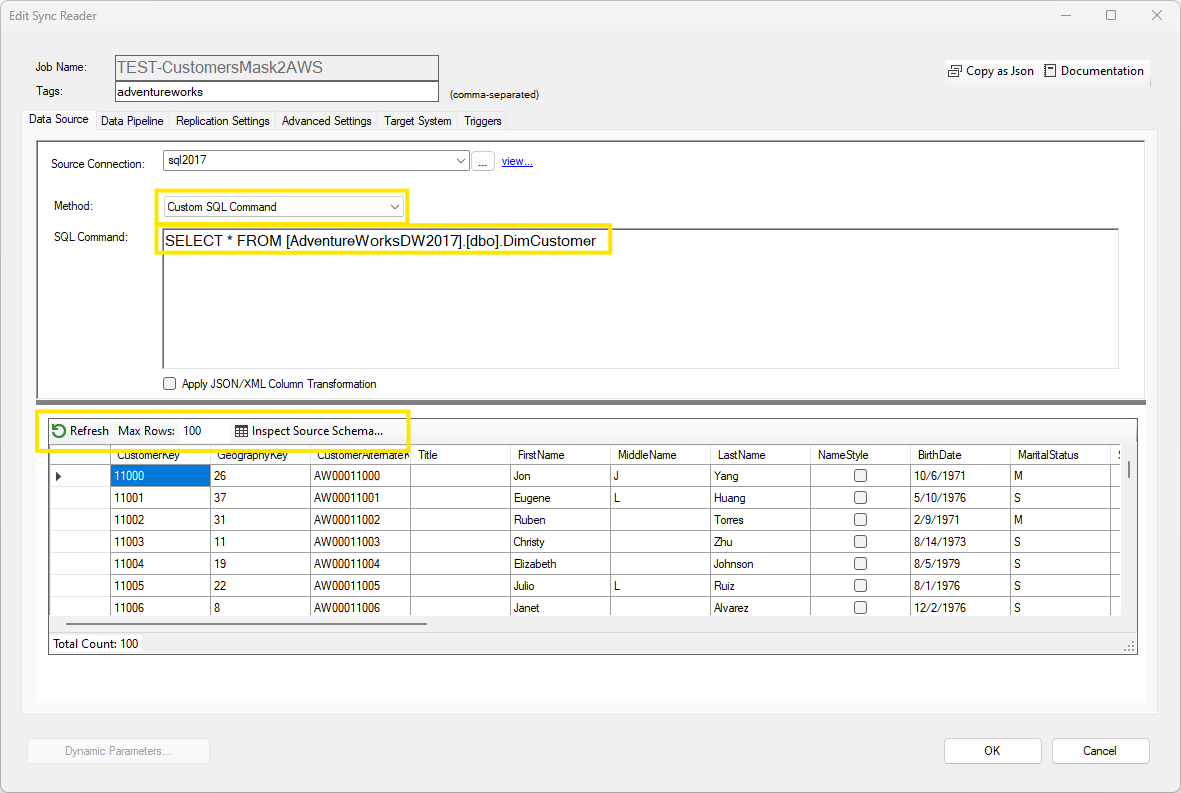
To extract data using an SQL command, select Custom SQL Command from the Method dropdown box, then enter the SQL command in the native query language of the database engine or the ODBC driver. Although any command can be executed, it is recommended to use a simple SELECT operation whenever possible; doing so enables DataZen to perform internal optimizations to read data in sets of rows to minimize impact on memory.
Click on the preview link to refresh the output. If the SQL command is a SELECT operation, you can also limit the number of records dispayed by changing the Max Rows setting.
Multiple options available on other tabs require you to preview the data so that schema and sample data is available.
You can use the @highwatermark token directly as part of your SQL command. If the SQL command
is a simple SELECT operation, the use of the token is optional; the SQL command will be automatically modified
to filter the data on the correct field as specified in the Replication Settings tab.
When executing complex commands, or calling stored procedures, using this token is necessary to leverage the
high watermark option.
Using an SQL Command with XML/JSON Conversion
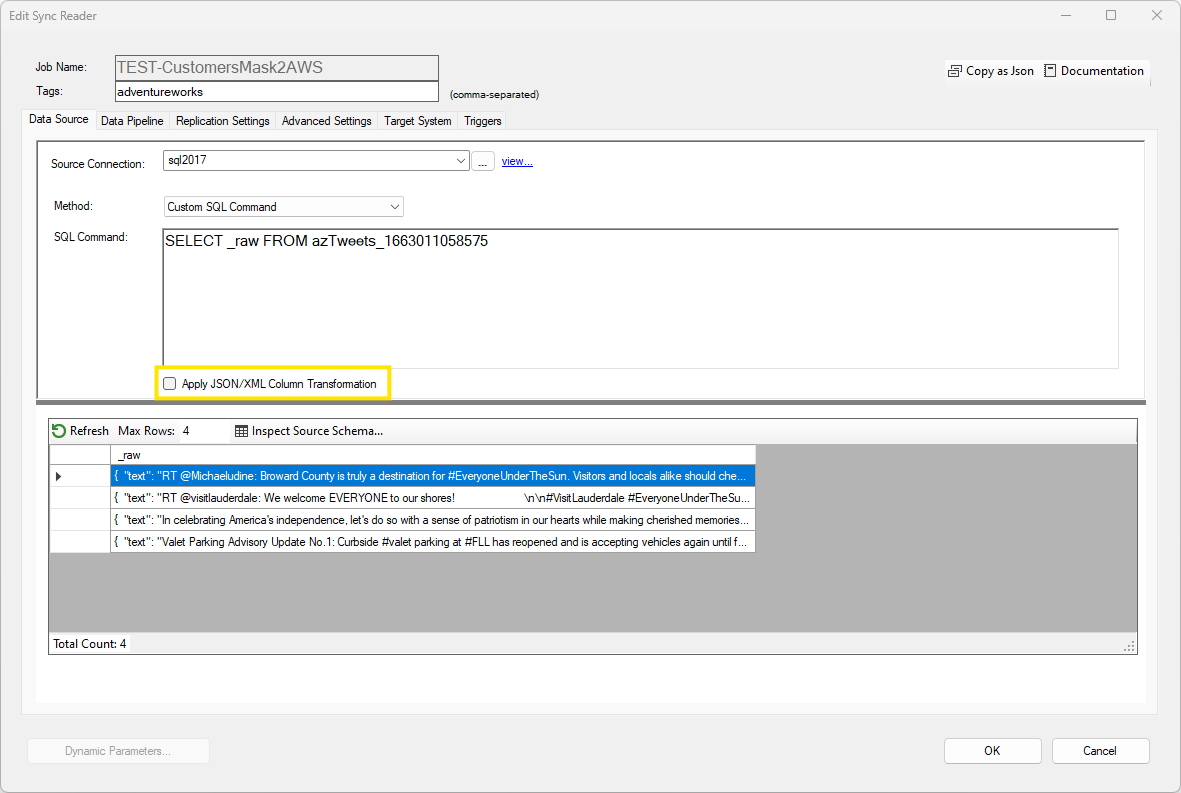
If the data returned by the SQL command contains a raw JSON/XML document, and this is the only information you need to extract, you can convert the document into rows and columns by selecting the Apply JSON/XML Column Transformation.
As an example, the SQL command shown here returns the content of the _raw column (index 0) which contains a JSON payload from previous tweets.
The XML or JSON path provided is an extended version of the standard paths. See the Document Path documentation for more information.
To convert this JSON output into rows and columns, click on the Apply JSON/XML Column Transformation checkbox.
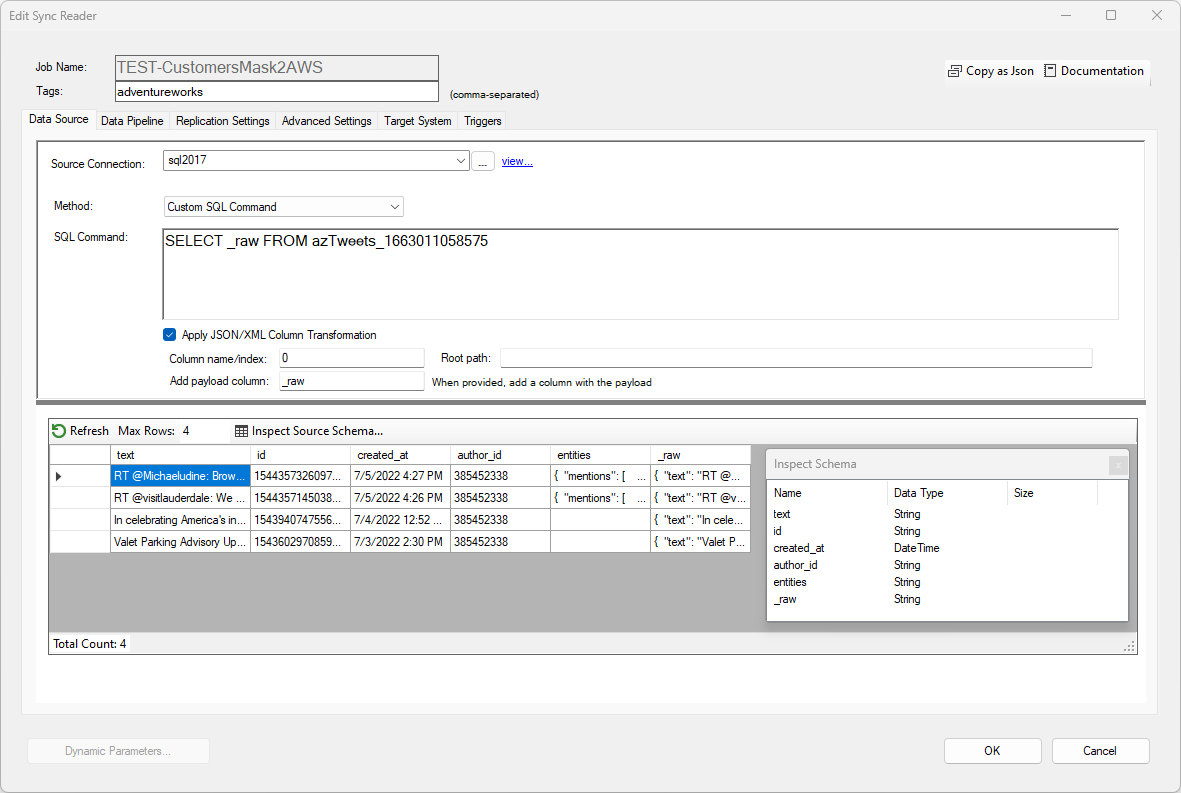
Enter 0 in the Column Name or Index field. Since we want to read from the root of the document, leave the Path field blank. Optionally, specify the name of an extra column that should contain the source document. In this example, the extra column name is _raw, but it could be anything.
Click the preview link to see the data transformed into rows and columns.
Most data types are selected automatically by DataZen based on a sample of the data returned; however, date/time fields are never converted to a date format. You can use the data pipeline to shape the schema more precisely.
Using SQL Server CDC or Change Tracking
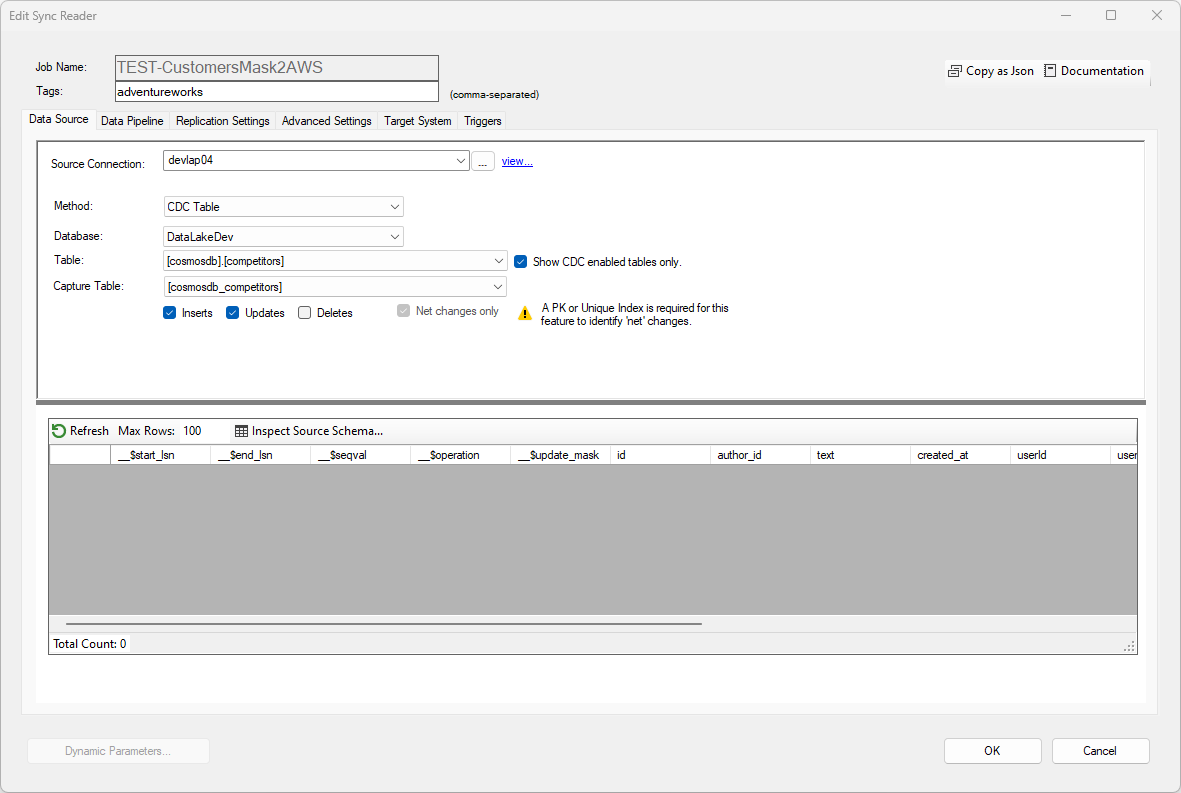
To choose a Change Tracking or CDC Table as the source of data for an existing SQL Server database, choose the appropriate option in the Method dropdown box.
Setting up Change Tracking and/or CDC in SQL Server requires advanced knowledge of the SQL Server engine. While DataZen provides options to quickly configure these settings it is recommended that a database administrator perform them instead for production systems.
Using non-SQL Server CDC Tables
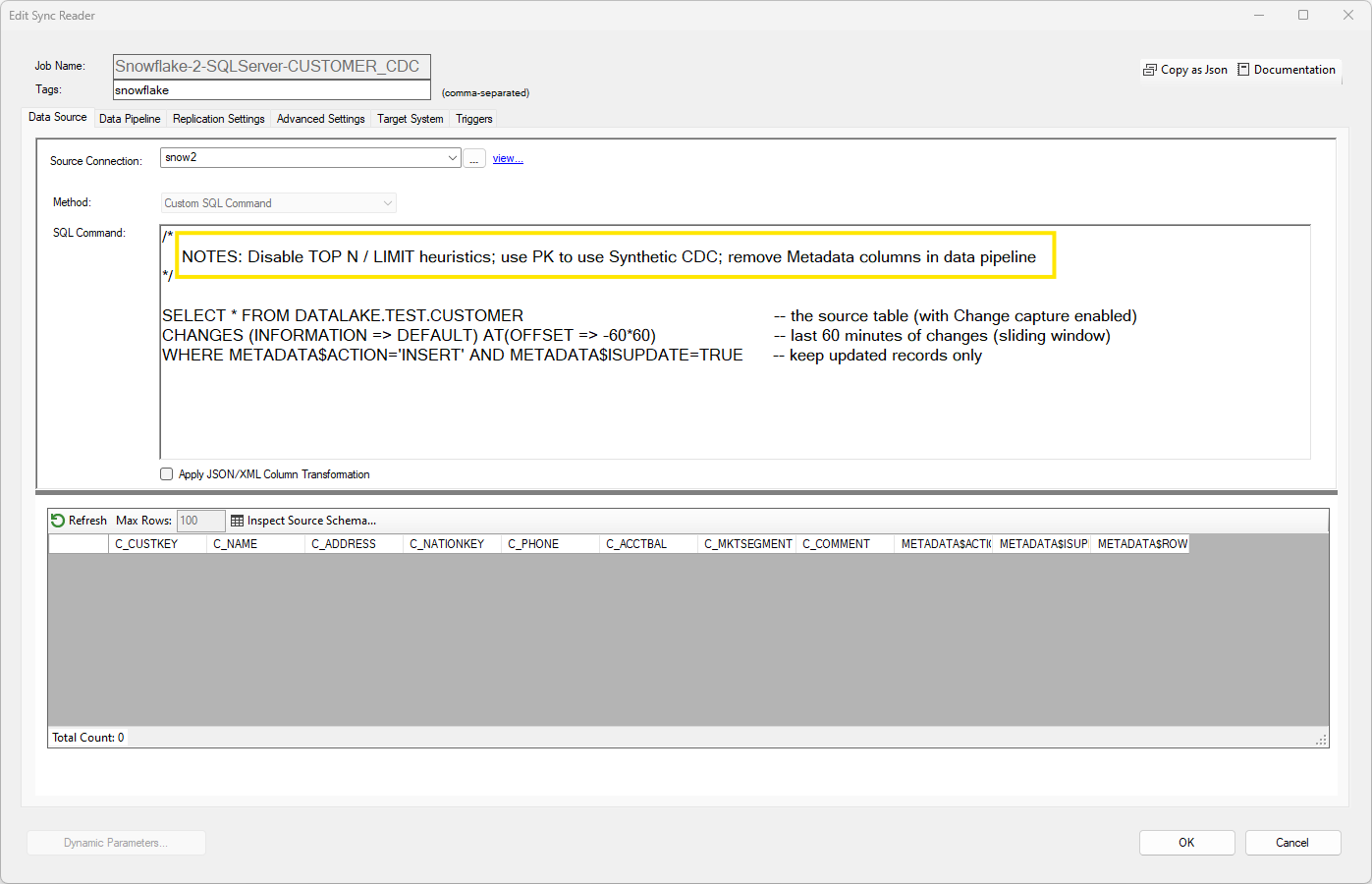
Although DataZen is optimized to read from SQL Server CDC and Change tracking tables, you can also read from non-SQL Server CDC tables, such as Oracle and Snowflake. Setting up this operation requires
Setting up CDC in Snowflake or other relational database requires advanced knowledge of the database engine. In this example, CDC is enabled on a Snowflake table. In addition, since DataZen is turning control over to the source system for tracking changes, a Synthetic CDC operation must be added to discard duplicate records within the operating sliding window.
It is highly recommended to disable TOP N Heuristics and remove metadata columns from the data set within the data pipeline.