One-Way Sync
A one-way sync composite pattern implements a data replication topology that keeps two or more systems synchronized for inserts, updates, and optionally deletes. It assumes that one system is used as the System of Record (SoR) for the data in scope, and that the target systems will eventually receive and accept incoming changes.
This pattern allows great flexibility on the target system, including the ability to manually add orphan records and additional fields. These considerations may impact the implementation presented in this documentation in order to accommodate the desired result and normally result in treating the target system as a source itself in order to dynamically infer changes.

Pattern Overview
This pattern describes a mechanism to keep records between two or more systems synchronized, assuming one system
is the System of Record (always containing the latest information). For example, if Quickbooks Online (QBO) is used to
create invoices, and a relational database contains a copy of these invoices, the SoR is assumed to be QBO because
any new invoice, or updates to invoices, can only happen in QBO.
Some integration scenarios can be more complex, when the target system can itself be used to modify other records.
For example, if the Medius AP SaaS platform is used to approve or reject invoices created in QBO, the state of
these invoices in QBO may need to be modified through additional integration pipelines.
DataZen Implementation
Implementing this pattern in DataZen is a multi-step process since it requires the use of both a reader and writer operation.
Step 1: Source Changes
First, you should decide which pattern you will be using when reading from the source system. The selection of the pattern depends on the capabilities of the source system and may be changed at virtually any time. In general, if the source system supports high watermarks, the Watermark pattern will be the most efficient.
- CDC Stream
- Watermark
- Synthetic CDC
- Window Capture
- Watermark + CDC
Step 2: Target Changes
Next, you will need to decide whether changes from the source system can be sent directly to the target system "as-is", or if you need to store the data in a stage database first. A few scenarios may require staging the data first, including:
- The target system may contain additional fields, and their values must be part of the Update operation to keep them intact
- The target system may allow records to be deleted, and the records should be recreated
However, if the target system cannot be modified externally, you may be able to forward the changes directly into the target system without staging the data.
Step 3: Push Changes
The last step consists of pushing changes to the target system; the approach differs depending on whether Step 2 required the creation of a staging database or not.
- Direct: a writer can be created as part of the same pipeline job
- Staged: a seperate pipeline job must be created by first reading both staged tables
Direct Push
Pushing data directly from source to target is a trivial pattern requiring a single pipeline job with a Reader operation
as discussed in Step 1, and a single Writer that pushes data into the target system as needed.
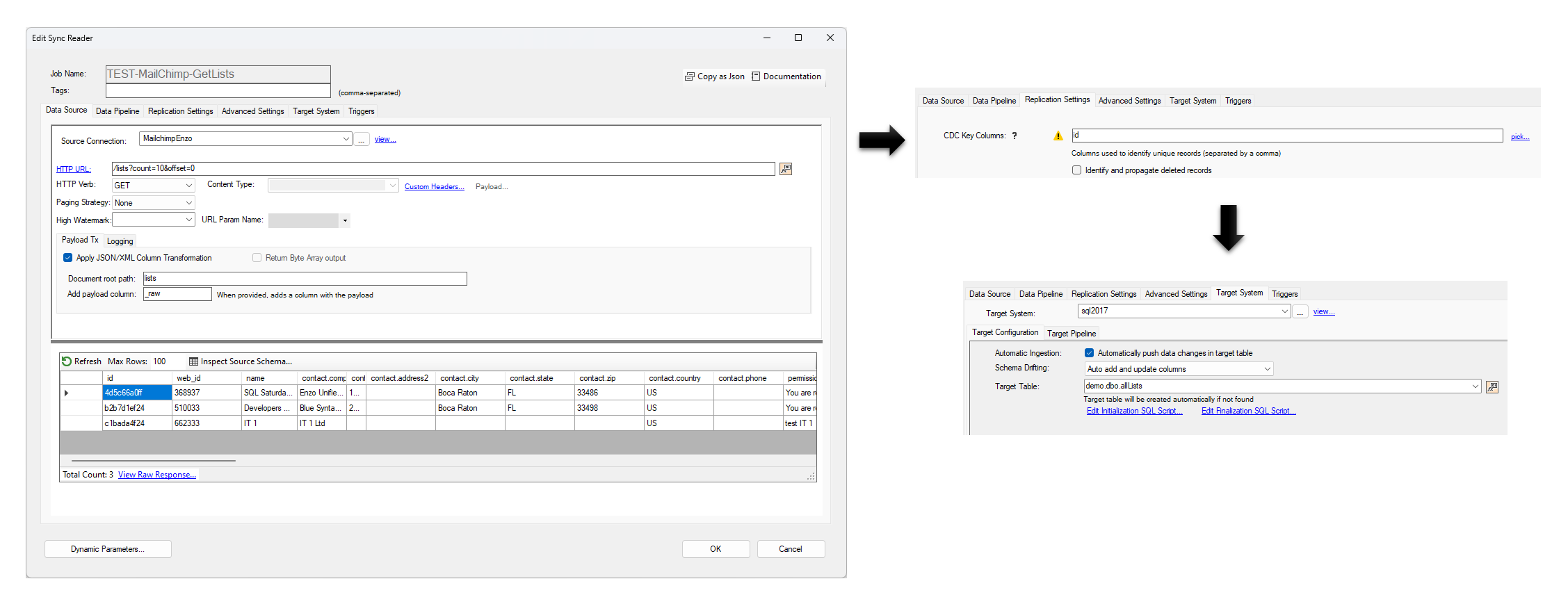
In this example, a direct job is created that reads from MailChimp and pushes new and updated records into
a relational database using a Change Capture pattern.
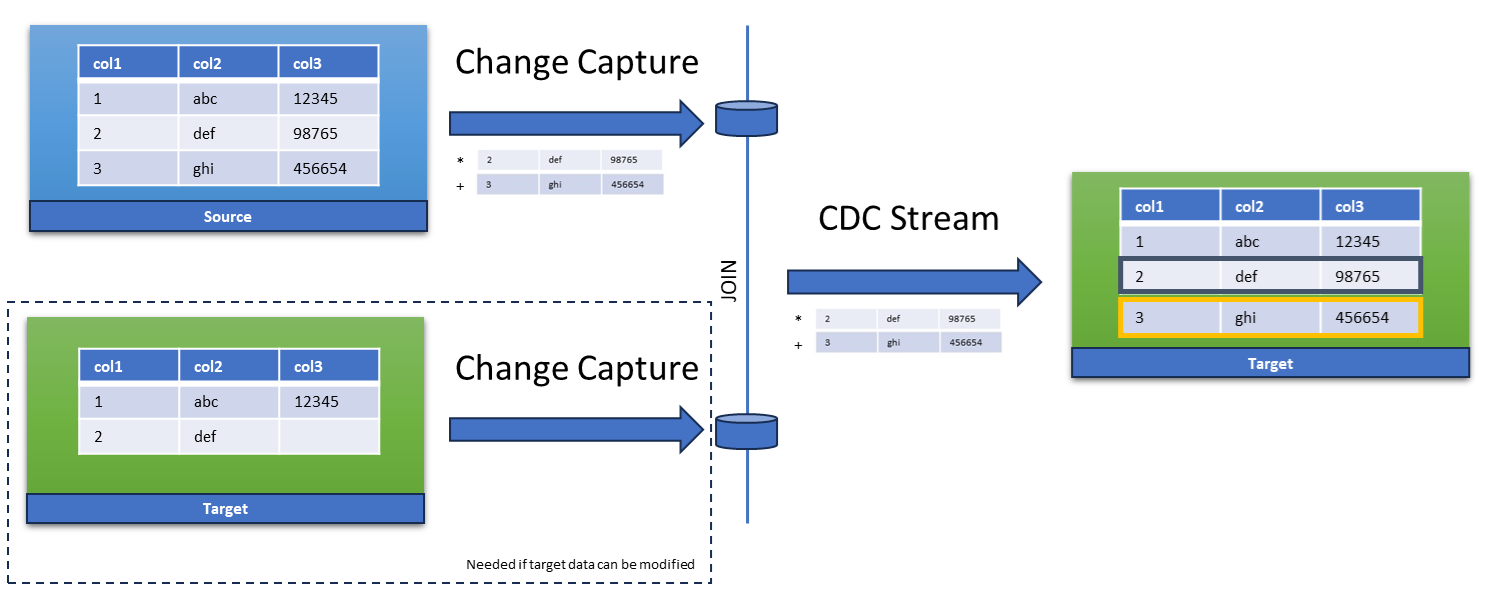
Staged Push
A staged push requires multiple pipelines in order to logically determine which records need to be pushed, and how.
In this diagram, the data from the source system is staged using the CDC pattern; the target system may also be staged as
discussed in Step 2. When both source and target systems are staged, a simple logical SQL operation is then needed that
joins both tables in order to determine which records are missing in the target system; this logical SQL operation
essentially becomes a CDC Stream itself.