Job Writer: Databases, ODBC Drivers, Enzo Server
To send data to a relational database, or an ODBC driver, choose the database connection to use. The data contained in the Change Log holds two separate streams: upserted records and deleted records.
An Upserted record represents data that is new or has been updated since it was last captured. The custom SQL command you provide for the target database must have the necessary logic to perform an Insert if the record is not found or an Update operation if it already exists. This is normally only possible if the data contains a unique identifier.
Cloud agents do not support all relational databases. See the Connections Overview for more information.
Automated Ingestion
When using SQL Server, Fabric, MySQL, PostgreSQL, or Snowflake as a target, you can use the recommended Automatic Ingestion option. This option automatically creates the Upsert and Delete scripts based on the database engine so you do not have to build them manually. The Schema Drifting option, if enabled, allows DataZen to also upgrade the schema as needed. The following schema drifting options are available:
- None: no schema drifting
- Auto add columns: adds new columns when the source data contains columns not found but existing data types are not modified
- Auto update types: modifies existing column data types as needed, but no new columns are added
- Auto add and update: allows both addition of new columns and modify data types are needed
When the option to update data types is selected, DataZen attempts to choose the next most restrictive data type (ex: from integer to long). If the data contains an incompatible data type (from example 'abc' is now a valid value for a long data type column), the column is converted to a string data type.
Example: SQL Server Target
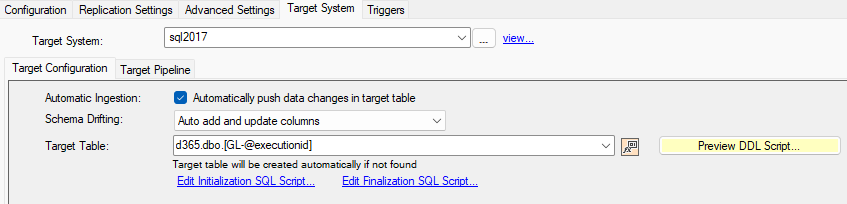
In this example, the settings use a SQL Server target with the option to automatically add and update the target columns to handle schema drifting. The name of the table is different for each execution since it contains the @executionid variable. The table name contains a three-part name in this example, forcing the use of the d365 database and the dbo schema. If the database name is not provided here, the one specified by the connection string will be used.
d365.dbo.[GL-@executionid]
Target Table
The name of the target table to use is entered in the Target Table field. You can use DataZen functions to calculate the name of the table at execution time as shown in the previous example. This feature is supported for all database platforms, including SQL Server, Oracle, MySQL, Teradata and more. For ODBC drivers, additional options are also provided.
DataZen always tries to create the target table if it doesn't exist in the database. You can click on the Preview DDL Script button to preview the DDL script that will be used by DataZen; you can also execute the DDL script yourself and modify it to add indexes or other constraints.
Initialization / Finalization Scripts
You can execute a SQL script before and after the execution of the job. You can use DataZen functions as part of the script; doing so will modify the script before it is executed. You can use this feature to truncate target tables before execution or trigger the execution of other procedures upon completion.
The script provided here also support DataZen functions, along with job parameters. However, the Finalization Script also supports the following additional parameter:
- @status: a string containing 'success' or 'failure', or the integer 1 or 0 respectivelly, which indicates whether the job completed successfully or not
The @totalwrite and @startindex parameters do not apply to this setting.
Custom SQL Scripts
Two custom scripts be be specified: an Upsert and a Delete script. The Upsert script is executed first. To build the script automatically, click on Generate ... Script.
The Max Batch Count represents the maximum number of records that will be processed at a time. The actual number of records within a given batch may be less that the batch count if the source data was read in smaller chunks. For example, if the source data was build from an HTTP/S reader using the Dynamic Parameter option, the Sync File may contain multiple smaller batches and will be processed separately; the actual number of records being processed will be the maximum between the Max Batch Count and the number of records available within each source batch.
To build an XML or JSON document from the input data, click on Insert JSON/XML document.... You can build a single document, or an array containing multiple records. When building an array, the Max Batch Count option represents the maximum number of records that the array will contain.
By default, this script will execute for every row that was modified in the source system. If you use the @concatjson, @concatjsonarr or @concatxml operator, the script will execute once per batch.
To preview the SQL script, click on Preview SQL....
If the target database is an ODBC driver, or an unknown system, a Scripting Engine dropdown will become visible, allowing to pick from one of the following database engines: SQL Server, Oracle, MySQL and Snowflake.
Example: MySQL Target
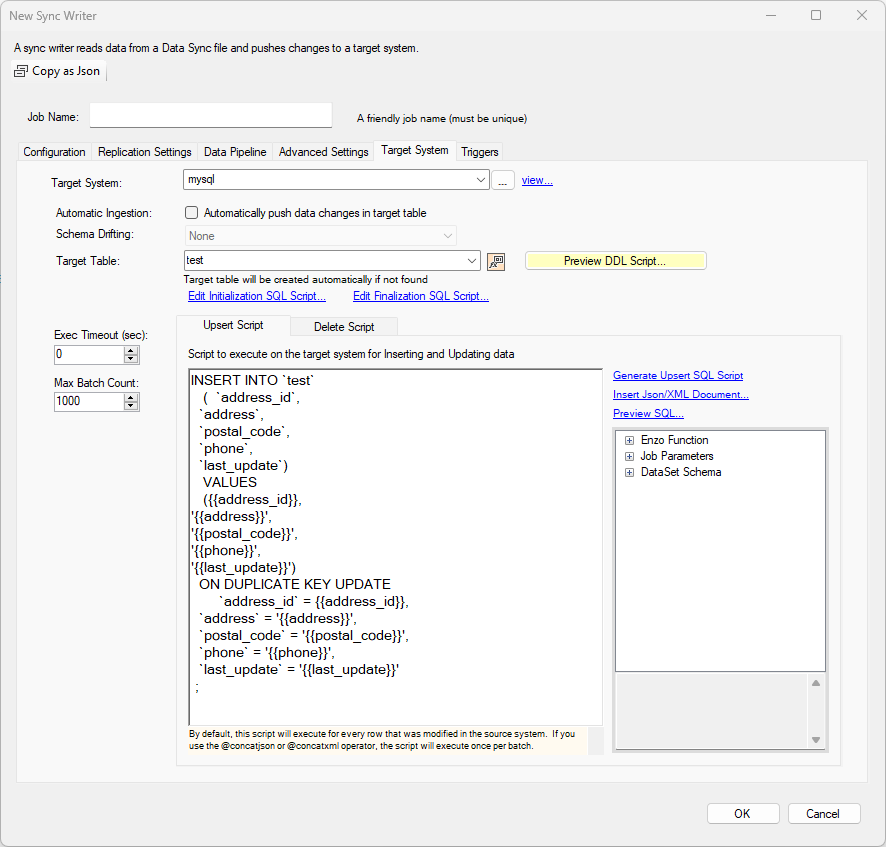
In this example, the settings use a MySQL Server target with a custom UPSERT script. The script was generaged automatically using the Generate Upsert SQL Script. Because DataZen knows the target is a MySQL database, the SQL generated will be optimized for this database platform.
The UPSERT operation depends on the creation of a primary key on the address_id field in the MySQL database table.
INSERT INTO `test`
( `address_id`,
`address`,
`postal_code`,
`phone`,
`last_update`)
VALUES
({{address_id}},
'{{address}}',
'{{postal_code}}',
'{{phone}}',
'{{last_update}}')
ON DUPLICATE KEY UPDATE
`address_id` = {{address_id}},
`address` = '{{address}}',
`postal_code` = '{{postal_code}}',
`phone` = '{{phone}}',
`last_update` = '{{last_update}}'
;
To generate a DELETE script, you must ensure to have previously selected a Key Column and have se;ected the Propagate deleted records in the Replication Settings tab. The DELETE script can also be generated automatically and would look similar to this command assuming the key is the address_id field:
DELETE FROM `test` WHERE `address_id` = {{address_id}};