Document Formatting
Formatting a document may be needed when sending HTTP/S requests with an HTTP Payload, when building database scripts, or when sending JSON or XML messages into a message hub. Formatting a document is almost always done in the context is the available data at the time the document is needed. If the document needs to be created as part of a data pipeline, the current pipeline schema will be available to build the document. When crafting a document in the Target area of a job, the schema available will essentially be the Target Pipeline's dataset.
Batching
The main difference between crafting a document within a data pipeline component and a target script is the availability of the Max Batch Count setting in the latter. Within a data pipeline, either the component will provide a "per row" operation, in which case you are building a document for a single record, or the document will be representing all the records in the current data pipeline. When building a target script however, you can control the batch and set it so 0 (all records), 1 (one record at a time), or any positive number greater than 1.
To view more information about formatting an HTTP Payload that contains a SQL command, see the HTTP SQL Payload section.
Single Document
When dealing with a single record, it may be easier to craft the document manually. In the example below, the {{soapAction}}
field is part of the dataset, and so are a few additional fields. Because this document is not using array concatenation, the
Match Batch Count must be set to 1 to ensure the endpoint is called for every incoming record.
<?xml version="1.0" encoding="utf-8" ?>
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:aut="http://model.v81.api.keysurvey.com">
<soapenv:Header />
<soapenv:Body>
<aut:{{soapAction}}>
<modelId>123456789</modelId>
<model>
<properties>
<entry>
<key>AccountKey</key>
<value>{{AccountKey}}</value>
</entry>
<entry>
<key>AccountDescription</key>
<value>{{AccountDescription}}</value>
</entry>
<entry>
<key>AccountType</key>
<value>{{AccountType}}</value>
</entry>
</properties>
<keyFieldName>AccountKey</keyFieldName>
</model>
</aut:{{soapAction}}>
</soapenv:Body>
</soapenv:Envelope>
Array of Objects
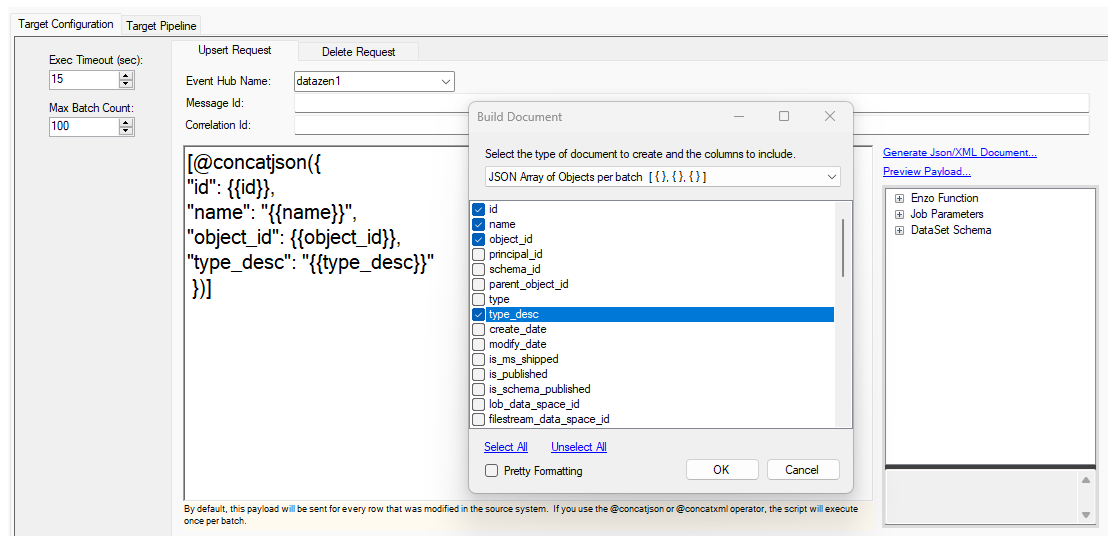
When building a document containing an array of items, such as a JSON array of objects, use the @concatjson operator and
add the surrounding brackets, or click on the Generate Json/XML Document... and choose the JSON Array of Objects option along
with the fields to include:
[@concatjson({
"id": {{id}},
"name": "{{name}}",
"object_id": {{object_id}},
"type_desc": "{{type_desc}}"
})]
Array of Arrays
Building an array of arrays is done using the @concatjsonarr operator, or by choosing the JSON Array of Values option.
This operator is useful with endpoints that are expecting array of values to be processed, such as Google Sheets or some
AI/ML endpoints.
[@concatjsonarr([ {{id}}, "{{name}}", {{schema_id}} ])]
XML Nodes
If you need to build an XML document that presents each record as a child node, use the @concatjson operator and add a
surrounding root note. You can also click on the Generate Json/XML Document... and choose the XML Document per Batch option along
with the fields to include:
<root>
@concatxml(<row><id>{{id}}</id>
<name>{{name}}</name>
<principal_id>{{principal_id}}</principal_id>
<parent_object_id>{{parent_object_id}}</parent_object_id><row>)
</root>
Binary Data
Sending binary data typically involves choosing which binary format should be used. Unless otherwise specified, DataZen sends
binary data as a base 64 encoded string. For example, if the bytes field contains binary data, the following HTTP
Payload would be send as a base 64 encoded value:
{{bytes}}
You can also use the base64 prefix explicitely:
{{base64:bytes}}
To send the binary data as an Hexadecimal string, use the
hex prefix instead:
{{hex:bytes}}
Database Scripts
Scripting for databases is similar conceptually to building a JSON or XML document. A single script can be generated for each incoming row of records, or a batch operation can be crafted that will send the desired number of changes at once. While batching strategies vary depending on the database engine, you can use DataZen's default scripts as a starting point. For example, sending a batch of changes to MySQL is different than for Snowflake or Oracle.
Script Generation
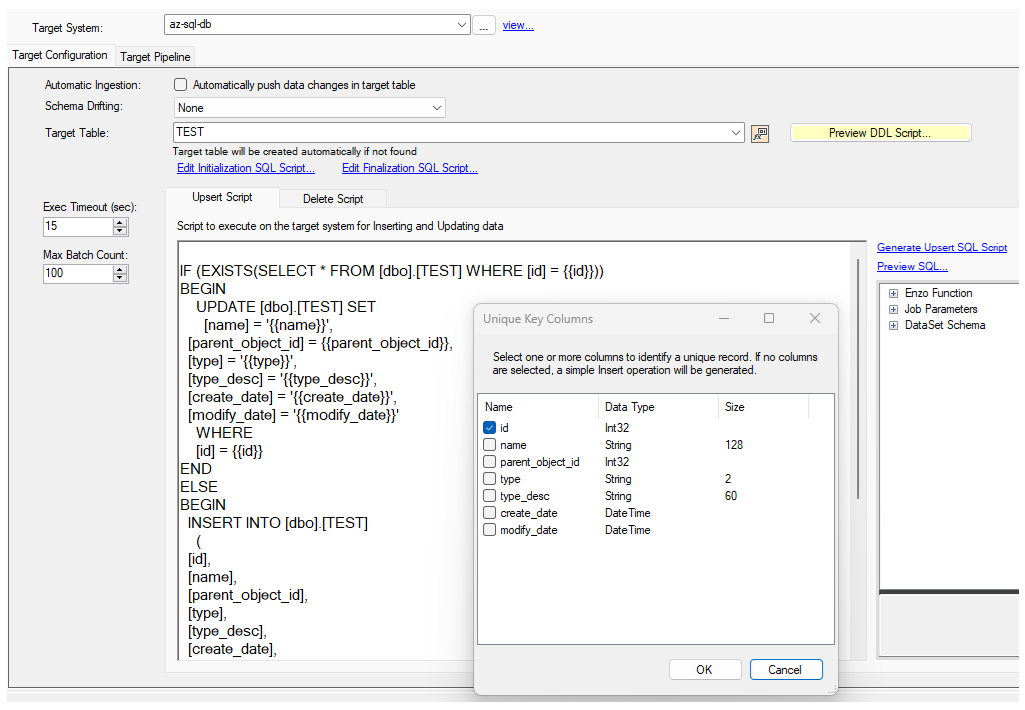
When building a script for a target database engine, all the available fields will be scripted. However, you can choose to either generate an INSERT only script, or an UPSERT script. Click on the Generate Upsert Script link, and choose which field(s) should be used as the unique record identifier; by default, the Job's CDC Key Field will be used as a hint to pre-select the correct fields, but you can choose different fields. If no fields are selected, an INSERT command will be generated instead of an UPSERT operation.