Introduction
DataZen is a data pipeline and replication platform that allows you to copy data from any source system into any target system, with optional automatic Change Data Capture (CDC), identifying and forwarding only the records that have actually changed. Because DataZen creates universal and portable Change Logs, data from source systems can be forwarded to virtually any target platform in the shape they are expected in.
In addition to moving data, DataZen also provides advanced data engineering functions that can accelerate data integration projects, including data masking, AI/ML endpoints to enhance data, external HTTP/S functions (including AWS Lambda and Azure Functions), data quality, schema management and more.
DataZen supports three primary use cases, as further explained below:
- Data Lake / Data Hub / Data Warehouse Generation or Augmentation
- Enterprise Messaging Bridge Integration
- Application and Data Integration
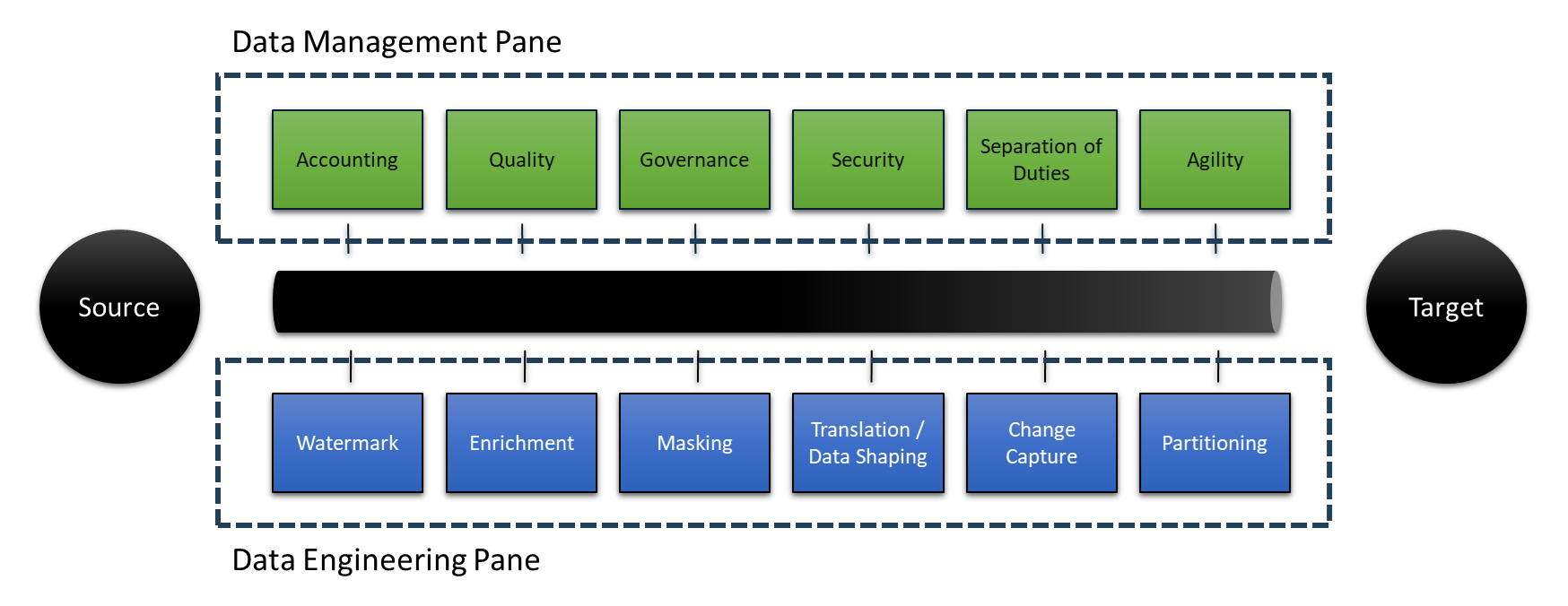
Engineering and Management Pane
A fundamental aspect of DataZen is its ability to provide both a management pane and a data engineering pane, allowing organizations to expose their data management practices. From a management standpoint, DataZen provides clear data transfer accounting in addition to performance metrics; these can be used, for example, to measure Service Level Agreements with external SaaS platforms and monitor response times. Other management aspects include the ability to govern access to all data sources and targets centrally, removing the need to expose secrets to team members unnecessarily. From a security standpoint, the DataZen architecture allows organizations to implement a zero-trust data integration policy through the least privilege principle, where each system is fully decoupled from the rest of the organization.
From an architectural standpoint, DataZen supports the implementation of a large number of data integration patterns and enables data engineering teams to leverage pre-built functions to accelerage integration projects. For more information on integration patterns, see the Data Pipeline Patterns Overview section which outlines three types of pattern categories: Stateless, Stateful, and Composite.
Use Cases
DataZen supports the following high-level use cases:
Data Lake / Data Hub / Data Warehouse Generation or Augmentation
Build or augment and existing Data Lake (or Hub or Warehouse) from any source system, including social media feeds, SaaS platforms, SharePoint Online, databases and more. This allows you to build different types of stores, such as a Data Vault or a specialized Data Lake for your reporting or operational needs. HTTP/S Sources When the source is an HTTP/S endpoint, leverage DataZen's built-in support for OpenAPI, Swagger, Yaml, and Postman collections for faster setup. DataZen can keep the necessary high watermarks and can be configured to handle paging as needed. Parquet Files / CSV Support DataZen supports Azure ADLS 2.0 and AWS S3 to simplify the creation of Delta Lakes using compressed Parquet files, simplifying your cloud integration architecture. You can also create comma-delimited files, JSON, or XML documents. Quick Integration with Azure Synapse and PowerBI Send your data to any target platform, including NO-SQL databases, relational databases platforms, or Parquet files to enable centralized reporting with PowerBI, Synapse Analytics, or other cloud analytical platforms. See our blog on SQL Server Replication to Azure Parquet Files in ADLS 2.0 for further information.
Enterprise Messaging Integration
As a Messaging Producer Forward any change from a source system to any supported messaging platform (including Kafka, MSMQ, RabbitMQ, Azure Event Hub...). If the source system does not offer a change capture feed, you can use DataZen's built-in Synthetic Data Capture engine to detect and forward changes to data only. As a Messaging Consumer Listen for messages from any supported messaging platform (Kafka, MSMQ, RabbitMQ...) and forward them to any other target system including databases, files, or HTTP/S endpoints. As a Messaging Exchange Platform Use DataZen's fully automatic messaging exchange engine to forward messages from one platform to another. For example, you can configure DataZen to forward MSMQ messages into an Azure Event Hub.
Application and Data Integration
Quickly extract changes from any source system and forward to any platform by leveraging the native CDC (Change Data Capture) feed of the source system, or use DataZen's built-in Synthetic CDC engine, so that only the desired changes are send to the target systems. Synthetic CDC When a source system doesn't provide the ability to push changes, you can use DataZen's Synthetic CDC Engine to filter out records that have not changed, and only keep the records that were modified, and optionally records that were deleted. Inline Data Pipeline Leverage DataZen's inline data pipeline to enhance your data, apply data masking rules, add or remove columns dynamically and more. Multiple Integration Patterns Replicate your data across platforms based on your objectives, with support for four integration patterns: Full Read,Window Read,CDC Read, and Window + CDC Read Replay Changes Keep DataZen's change logs and optionally replay previous changes on any target. Because change logs are portable, they can be archived and replayed in other DataZen environments.
Pipeline Architecture
To better understand how DataZen works, let's review the major components of the DataZen Pipeline architecture.
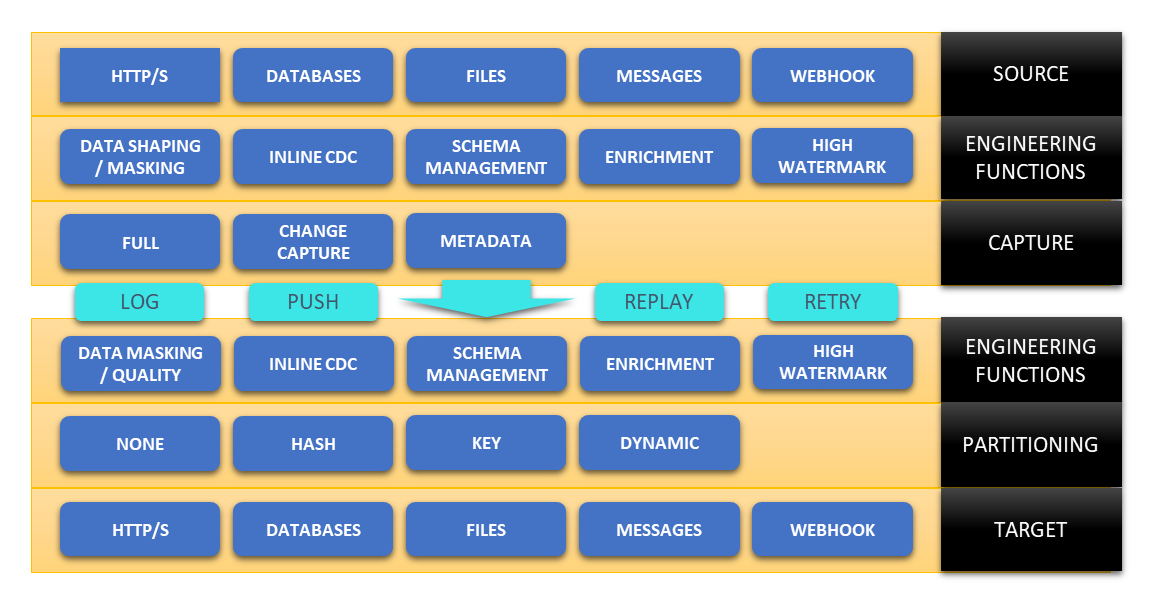
- READ / EXTRACT / RECEIVE
The DataZen reader is responsible for connecting and extracting source data (or accepts data as a webhook endpoint), which is optionally processed through a data pipeline and further reduced based on Change Capture settings.- Source: data is read from the source system (HTTP/S API, Database, ODBC, Enzo Server, Files...); uses an optional High Watermark to only read the necessary records
- Engineering Functions: data is optionally processed through an initial data pipeline and can be enriched, masked, reduced, and shaped as needed
- Capture: when Key Columns are identified, the DataZen Synthetic CDC engine eliminates records that have not changed or been deleted and stores schema information
-
LOG
Once the reader has completed, the captured data is stored in a change log and ready for consumption by a writer. The change log can be inspected and optionally replayed in the future against any endpoint. Because change logs are portable, they can also be copied on other systems. -
WRITE / PUSH
The DataZen writer is responsible for connecting to a target system and perform most of the the necessary data translations specific to the target system selected. Since DataZen decouples the target system from the data source, target systems can be added at any time as long as the change logs are still made available.- Engineering Functions: as the change log is being applied, data can optionally be further processed through a target-specific data pipeline to be enriched, masked, reduced, and shaped as needed
- Partitioning: before being applied to the target system, the data can be partitioned, depending on the target system
- Target: the data is then pushed to the target system, with optional batching and logging depending on the target system